Java-разработчик Владимир Фролов и Android-разработчик Никита Сизинцев из DataArt, составили краткий курс по многопоточности в Java из шести лекций
4.1 ПУЛЫ ПОТОКОВ RUNNABLE И CALLABLE
Создавать потоки для выполнения большого количества задач очень трудоемко: создание потока и освобождение ресурсов — дорогостоящие операции. Для решения проблемы ввели пулы потоков и очереди задач, из которых берутся задачи для пулов. Пул потоков — своего рода контейнер, в котором содержатся потоки, которые могут выполнять задачи, и после выполнения одной самостоятельно переходить к следующей.
Вторая причина создания пулов потоков — возможность разделить объект, выполняющий код, и непосредственно код задачи, которую необходимо выполнить. Использование пула потоков обеспечивает лучший контроль создания потоков и экономит ресурсы создания потоков. Также использование пула потоков упрощает разработку многопоточных программ, упрощая создание и манипулирование потоками. За созданием и управлением пулом потоков отвечают несколько классов и интерфейсов, которые называются Executor Framework in Java.
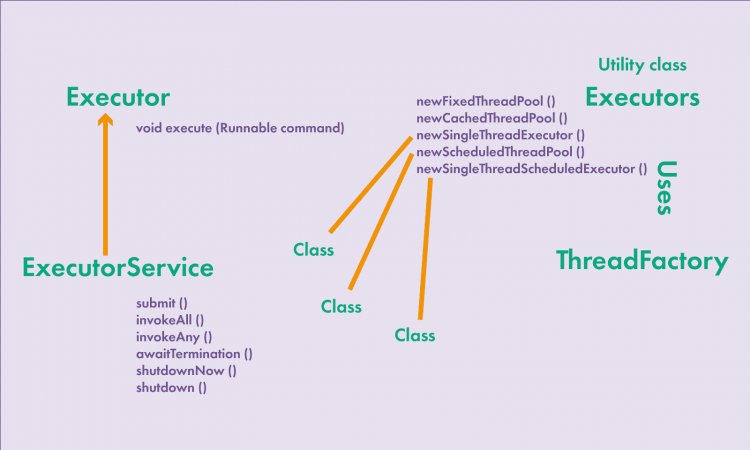
Рис 1: Упрощенное схематическое представление классов, отвечающих за пул потоков
Примечания к рисунку 1. Это не схема наследования классов и не UML-диаграмма, а простая структурная схема, которая показывает, кто что использует, какие есть методы и что получается в результате.
Рассмотрим основные интерфейсы и классы, входящие в этот фреймворк. Его основные интерфейсы: Executor, ExecutorService и фабрика Executors. Объекты, которые реализуют интерфейс Executor, могут выполнять runnable-задачу. Интерфейс Executor имеет один метод void execute(Runnable command). После вызова этого метода и передачи задачи на выполнение задача в будущем будет выполнена асинхронно. Также этот интерфейс разделяет, кто будет выполнять задачу и что будет выполняться, — в отличии от класса Thread.
Интерфейс ExecutorService наследуется от интерфейса Executor и предоставляет возможности для выполнения заданий Callable, для прерывания выполняемой задачи и завершения работы пула потоков. Для выполнения задач, которые возвращают результат, существует метод submit(), возвращающий объект, который реализует интерфейс Future<T>. С помощью этого объекта можно узнать, есть ли результат, вызовом метода isDone(). С помощью метода get() можно получить результат выполнения задачи, если он есть. Также можно отменить задание на выполнение при помощи метода cancel().
Класс Executors — утилитный клас, как например, класс Collections. Класс Executors создает классы, которые реализуют интерфейсы Executor и ExecutorService. Основные реализации пула потоков, т. е. реализации интерфейсов Executor и ExecutorServcie:
- ThreadPoolExecutor — пул потоков, который содержит фиксированное количество потоков. Также этот пул можно создать с использованием конструктора через ключевое слово new.
- Executors.newCachedThreadPool() возвращает пул потоков, если в пуле не хватает потоков, в нем будет создан новый поток.
- Executors.newSingleThreadExecutor() — пул потоков, в котором есть только один поток.
- ScheduledThreadPoolExecutor — этот пул потоков позволяет запускать задания с определенной периодичностью или один раз по истечении промежутка времени.
4.2 THREADFACTORY
Пул потоков использует класс, который реализует интерфейс ThreadFactory для создания потоков, чтобы один поток мог выполнять несколько Runnable- или Callable-объектов. Поток, который выполняет несколько объектов Runnable, называется Worker. Цепочка выполнения такая: ThreadPoolExecutor -> Thread -> Worker -> YourRunnable. По умолчанию используется класс Executors$DefaultThreadFactory. ThreadFactory — интерфейс с один методом Thread newThread(Runnable r). Стандартно именование потоков в пуле потоков pool-n-thread-m. Класс, который реализует ThreadFactory, используется, чтобы настроить поток для пула потоков. Например, установить имя или приоритет потока, установить ExceptionHandler для потока или сделать потоки внутри Executor демонами.
4.3 ЗАВЕРШЕНИЕ ВЫПОЛНЕНИЯ ПУЛА ПОТОКОВ
Для завершения работы пула потоков у интерфейса ExecutorService есть несколько методов: shutdown(), shutdownNow() и awaitTermination(long timeout, TimeUnit unit).
После вызова метода shutdown() пул потоков продолжит работу, но при попытке передать на выполнение новые задачи они будут отклонены, и будет сгенерирован RejectedExecutionException.
Метод shutdownNow() не запускает задачи, которые были уже установлены на выполнение, и пытается завершить уже запущенные.
Метод awaitTermination(long timeout, TimeUnit unit) блокирует поток, который вызвал этот метод, пока все задачи не выполнят работу, или пока не истечет таймаут, который передан при вызове метода, или пока текущий ожидающий поток не будет прерван. В общем, пока какое-то из этих условий не выполнится первым.
4.4 ОТМЕНА ЗАДАЧ В EXECUTORS
После передачи Runnable или Callable возвращается объект Future. Этот объект имеет метод cancel(), который может использоваться для отмены задания. Вызов этого метода имеет разный эффект в зависимости от того, когда был вызван метод. Если метод был вызван, когда задача еще не начала выполняться, задача просто удаляется из очереди задач. Если
задача уже выполнилась, вызов метода cancel() не приведет ни к каким результатам.
Самый интересный случай возникает, когда задача находится в процессе выполнения. Задача может не остановиться, потому что в Java задачи полагаются на механизм называемый прерыванием потока. Если поток не проигнорирует этот сигнал, поток остановится. Однако он может и не отреагировать на сигнал прерывания.
Иногда необходимо реализовать нестандартную отмену выполнения задачи. Например, задача выполняет блокирующий метод, скажем, ServerSocket.accept(), который ожидает подключения какого-то клиента. Этот метод игнорирует любые проверки флага interrupted. В представленном выше случае для остановки задачи необходимо закрыть сокет, при этом возникнет исключение, которое следует обработать. Есть два способа реализации нестандартного завершения потока. Первый — переопределение метода interrupt() в классе Thread, который не рекомендуется использовать. Второй — переопределение метода Future.cancel(). Однако объект Future — интерфейс, и объекты, которые реализуют этот интерфейс, пользователь не создает вручную. Значит, надо найти способ, который позволит это сделать. И такой способ есть. Объект Future возвращается после вызова метода submit(). Под капотом ExecutorService вызывает метод newTaskFor(Callable<V> c) для получения объекта Future. Метод newTaskFor стоит переопределить, чтобы он вернул объект Future с нужной функциональностью метода cancel().
Листинг 1:
import java.util.concurrent.BlockingQueue;
public class CustomFutureReturningExecutor extends ThreadPoolExecutor {
public CustomFutureReturningExecutor(int corePoolSize,
int maximumPoolSize, long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
if (callable instanceof IdentifiableCallable) {
return ((IdentifiableCallable<T>) callable).newTask();
} else {
return super.newTaskFor(callable);
}
}
}
Листинг 2:
import java.util.concurrent.*;
public interface IdentifiableCallable<T> extends Callable<T> {
int getId();
RunnableFuture<T> newTask();
void cancelTask();
}
Дальше необходимо определить класс FutureWarapper, для того чтобы можно было переопределить метод cancel();
Листинг 3:
import java.util.concurrent.*;
public abstract class FutureTaskWrapper<T> extends FutureTask<T> {
public FutureTaskWrapper(Callable<T> c) {
super(c);
}
abstract int getTaskId();
}
Класс FutureTask реализует одновременно Runnable и Callable. Этот класс представляет базовую реализацию интерфейса Future и предназначен для добавления новой функциональности. Дальше следует определить задание, которое будет выполняться в в Executor:
Листинг 4:
class Task implements IdentifiableCallable<Boolean> {
private final int id;
volatile boolean cancelled; // Cancellation flag
public Task(int id) {
this.id = id;
}
@Override
public synchronized int getId() {
return id;
}
@Override
public RunnableFuture<Boolean> newTask() {
return new FutureTaskWrapper<Boolean>(this) {
@Override
public boolean cancel(boolean mayInterruptIfRunning) {
Task.this.cancelTask();
return super.cancel(mayInterruptIfRunning);
}
@Override
public int getTaskId() {
return getId();
}
};
}
@Override
public synchronized void cancelTask() {
cancelled = true;
}
@Override
public Boolean call() {
while (!cancelled) {
// Do Samba
}
System.out.println("bye");
return true;
}
}
В листинге 4 из метода newTask() возвращается класс, который унаследован от класса FutureTaskWrapper. В конструктор этого класса передается ссылка this (объект Callable), необходимая для корректного создания объекта Futuretask. В листинге 5 приведен код главного класса программы, который запускает усовершенствованный ExecutorService.
Листинг 5:
import java.util.concurrent.*;
public class FutureTaskWrapperConcept {
public static void main(String[] args) throws Exception {
ExecutorService exec = new CustomFutureReturningExecutor(1, 1,
Long.MAX_VALUE, TimeUnit.DAYS,
new LinkedBlockingQueue<Runnable>());
Future<?> f = exec.submit(new Task(0));
FutureTaskWrapper<?> ftw = null;
if (f instanceof FutureTaskWrapper) {
ftw = (FutureTaskWrapper<?>) f;
} else {
throw new Exception("wtf");
}br
try {
Thread.sleep(2000);
} catch (InterruptedException ignored) {
}br System.out.println("Task Id: " + ftw.getTaskId());
ftw.cancel(true);
exec.shutdown();
}
}
Теперь при вызове метода cancel() будет выполнена нестандартная логика по отмене задачи.
4.5 ОБРАБОТКА ИСКЛЮЧЕНИЙ.
Для обработки исключений, которые возникают при выполнении объектов Runnable, устанавливается обработчик исключений в ThreadFactory, затем ThreadFactory устанавливает потоку:
Листинг 6:
public class ExceptionHandler implements Thread.UncaughtExceptionHandler {
@Override
public void uncaughtException(Thread thread, Throwable t) {
System.out.println("Uncaught exception is detected! " + t + " st: " +
Arrays.toString(t.getStackTrace()));
}
}
public class CustomThreadFactory implements ThreadFactory {
private final Thread.UncaughtExceptionHandler handler;
public CustomThreadFactory(Thread.UncaughtExceptionHandler handler) {
this.handler = handler;
}
@Override
public Thread newThread(Runnable run) {
Thread thread = Executors.defaultThreadFactory().newThread(run);
thread.setUncaughtExceptionHandler(handler);
return thread;
}
}
public class ExceptionHandlerExample {
public static void main(String[] args) throws InterruptedException {
ThreadFactory threadFactory =
new CustomThreadFactory(new ExceptionHandler());
ExecutorService threadPool =
Executors.newFixedThreadPool(4, threadFactory);
Runnable r = () -> {
throw new RuntimeException("Exception from pool");
};
threadPool.execute(r);
threadPool.shutdown();
threadPool.awaitTermination(10, TimeUnit.SECONDS);
}
}
В Листинге 6 создается обработчик исключений, который передается фабрике потоков. Создается пул из четырех потоков с использованием переданной фабрики. При возникновении исключения оно перехватывается обработчиком исключения ExceptionHandler. Такой способ подходит, когда пул поток выполняет задачи Runnable. Если исключение возникло при выполнении задания Callable<V>, при получении значения из объекта Future<V> будет сгенерировано ExecutionException. Пример в Листинге 7:
Листинг 7:
import java.util.concurrent.*;
public class ExceptionFromFutureObject {
public static void main(String[] args) throws InterruptedException {
ExecutorService threadPool3 = Executors.newFixedThreadPool(4);
Callable<String> c3 = () -> {
throw new Exception("Exception from task.");
};
Future<String> executionResult = threadPool3.submit(c3);
threadPool3.shutdown();
threadPool3.awaitTermination(10, TimeUnit.SECONDS);
try {
executionResult.get();
} catch (ExecutionException e) {
Throwable cause = e.getCause();
System.out.println(cause.getMessage());
}
}
}
Еще один способ обработки исключений в ExecutorService — использование Callable<V>. Если наследоваться от класса ThreadPoolExecutor, нужно учесть, что у него есть так называемые hook-методы:
void beforeExecute(Thread t, Runnable r) и void afterExecute(Thread t, Runnable r). Эти методы выполняются тем потоком, который будет выполнять непосредственно само задание. Если переопределить метод afterExecute(), исключения, которые будут сгенерированы в процессе выполнения задания, можно будет обработать в методе afterExecute. Пример в Листинге 8.
Листинг 8:
class ExtendedExecutor extends ThreadPoolExecutor {
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
if (t == null && r instanceof Future<?>) {
try {
Object result = ((Future<?>) r).get();
} catch (CancellationException ce) {
t = ce;
} catch (ExecutionException ee) {
t = ee.getCause();
} catch (InterruptedException ie) {
Thread.currentThread().interrupt(); // ignore/reset
}
}
if (t != null) {
System.out.println(t);
}
}
}
4.6 КЛАСС THREADPOLLEXECUTOR
Один из основных классов, которые генерирует фабрика Executors, — класс ThreadPoolExecutor. Рассмотрим основные параметры этого класса.
Параметры core and maximum pool size. ThreadPoolExecutor автоматически настроит размер пула потоков в соответствии с установленными значениями corePoolSize и maximumPoolSize. Когда пулу потоков передается новая задача, а количество работающих потоков меньше, чем corePoolSize, создается новый поток, даже когда другие потоки ничего не делают. Если количество запущенных потоков больше, чем corePoolSize, но меньше, чем maximumPoolSize, новый поток будет создан, если очередь задач заполнена. Если значения параметров corePoolSize и maximumPoolSize равны, создается пул потоков фиксированного размера. Если в качестве параметра maximumPoolSize передается неограниченное значение, например, Integer.MAX_VALUE, это позволяет пулу потоков выполнять произвольное количество задач. Класс ThreadPoolExecutor, как и другие классы пула потоков, использует очередь задач для передачи и удержания задачи для пула потоков.
При работе с очередью задач используют следующие правила:
- если количество задач меньше, чем параметр corePoolSize, пул потоков всегда отдаст предпочтение запуску нового потока;
- если количество работающих потоков больше или равно параметру corePoolSize, пул потоков предпочтет помещение задачи в очередь;
- если задача не может быть помещена в очередь, пул потоков попытается создать новый поток; если количество созданных потоков превышает значение maximumPoolSize, задача будет отклонена и передана RejectedExecutionHandle для последующей обработки.
4.7 FORK/JOIN POOL
С выходом Java 7 в арсенале разработчиков появился новый фреймворк Fork/Join Poll. В Java 8 Fork/Join pool создается по умолчанию, когда мы вызываем метод parallel() для параллельной обработки данных. Также Fork/Join pool используется в классе CompletableFuture. Класс ForkJoinPool реализует интерфейсы Executor, ExecutorService. Класс ForkJoinPool можно создать через ключевое слово new и через класс Executors.newWorkStealingPool().
ForkJoinPool использует способ, когда одна задача разделяется на несколько мелких, которые выполняются по отдельности, а затем полученные ответы объединяются в единый результат. В Fork/Join Pool есть много методов, однако используются в основном три: fork(), compute() и join(). Метод compute() содержит изначально большую задачу, которую необходимо выполнить. В методе compute() используется один и тот же шаблон: если задача слишком большая, она разбивается на две или большее количество подзадач, если задача достаточно маленькая, согласно условиям, заданным программистом, она выполняется в методе compute(). Пример псевдокода — в Листинге 9.
Листинг 9:
if(Task is small) {
Execute the task
} else {
//Split the task into smaller chunks
ForkJoinTask first = getFirstHalfTask();
first.fork();
ForkJoinTask second = getSecondHalfTask();
second.compute();
first.join();
}
К каждому потоку, который правильнее было бы называть воркером, в Fork/Join пуле назначена очередь — dequeue. Изначально очереди пустые, и потоки в пуле без работы. Переданная в Fork/Join pool основная задача (top-level) помещается в очередь, предназначенную для top-level задач. Для этого процесса существует отдельный поток, который запускает еще несколько потоков, которые будут непосредственно участвовать в обработке подзадач. Это сделано, чтобы не тратить время на запуск потоков Fork/Join пула в дальнейшем. Усредненное время запуска потока на операционных системах типа Linux на JVM — около 50 мкс. Однако если запускать несколько потоков одновременно, времени требуется больше, а для некоторых приложений даже совсем небольшая задержка оказывается критической.
После вызова метода fork() задача будет разбита на две или более подзадач и помещена в очередь текущего потока. Полученные задачи кладутся в голову очереди. Текущий поток также получает задачи из головы очереди. Этот подход применен, чтобы поток работал со своей очередью без синхронизации. Другие потоки, которые хотят украсть задачи из очереди, получают задачи из хвоста очереди — там используется синхронизация.
В псевдокоде в Листинге 9 вызывается метод compute() для выполнения второй части задачи.
Предположим, что первая часть задачи будет украдена другим потоком, он, в свою очередь, разобьет первую подзадачу еще на две подзадачи, и процесс будет повторяться, пока задачи не станут достаточно малыми для их выполнения без разбивки. Порог, до которого следует разбивать задачи, рекомендуется выбирать исходя из следующего условия:
ThreshHold = N / (C*L), где N — это размер задачи, L — так называемый load factor. Это число имеет порядок от 10 до 100 — по сути это количество задач, которое выполнит один воркер, умноженное на С — количество воркеров в пуле.
Есть несколько базовых подходов для распределения задач в threadpoll`ах:
- Work arbitrage — общий арбитр раздающий задачи. Например, это очередь задач в ThreadPollExecutor. Есть общая очередь задач, и воркеры берут из этой очереди задачи на выполнение.
- Work dealing — воркер, у которого очень много задач, передает задачи другим потокам. В этом способе есть недостаток: если поток загружен, ему надо тратить время на поиск свободных потоков вместо выполнения задач.
- Work stealing — если у воркера нет задач на выполнение, поток может украсть задачи из очереди другого потока. Этот алгоритм используется в Fork/Join poll. Также алгоритм кражи задач используется для более равномерного перераспределения задач между всеми потоками в пуле.
ForkJoinPoll принимает сущность ForkJoinTask<V> по аналогии Runnable или Callable<V>. Это абстрактный класс, он реализует интерфейс Future<V> и от этого класса наследуются два класса RecursiveAction и RecursiveTask, которые имеют только один абстрактный метод compute(). Разница между этими двумя классами в том что RecursiveTask может возвращать результат, а RecursiveAction ничего не возвращает. RecursiveAction может, например, использоваться для сортировки каких-то значений. Пример использования ForkJoinPool — в листинге 10.
Листинг 10:
public class ForkJoinPoolTest {
public static void main(String[] args) {
int[] array = yourMethodToGetData();
ForkJoinPool pool = new ForkJoinPool();
Integer max = pool.invoke(new FindMaxTask(array, 0, array.length));
System.out.println(max);
}
static class FindMaxTask extends RecursiveTask<Integer> {
private int[] array;
private int start, end;
public FindMaxTask(int[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start <= 3000) {
int max = -99;
for (int i = start; i < end; i++) {
max = Integer.max(max, array[i]);
}
return max;
} else {
int mid = (end - start) / 2 + start;
FindMaxTask left = new FindMaxTask(array, start, mid);
FindMaxTask right = new FindMaxTask(array, mid + 1, end);
ForkJoinTask.invokeAll(right, left);
int leftRes = left.getRawResult();
int rightRes = right.getRawResult();
return Integer.max(leftRes, rightRes);
}
}
}
}
В листинге 10 вместо вызова методов fork(), compute() и join() вызывается метод ForkJoinTask.invokeAll(), который делает то же самое, что и три эти метода. В Листинге 11 приведен пример использования класса RecursiveAction. В программе создаются вымышленные продукты, им назначаются имена, а затем в fork/join poll на них устанавливается цена.
Листинг 11:
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) throws InterruptedException {
List<Product> products = generate(10000);
Task task = new Task(products, 0, products.size());
ForkJoinPool pool = new ForkJoinPool();
pool.execute(task);
while (!task.isDone());
pool.shutdown();
if (task.isCompletedNormally()) {
System.out.print("Main: The process has completed normally.\n");
}
for (Product product : products) {
System.out.printf("Product %s: %d\n", product.getName(),
product.getPrice());
}
System.out.println("Main: End of the program.\n");
}
private static List<Product> generate(int size) {
return IntStream.rangeClosed(1, size)
.mapToObj(i -> {
Product product = new Product();
product.setName("Product " + i);
product.setPrice(10);
return product;
}).collect(Collectors.toList());
}
}
import java.util.List;
import java.util.Random;
import java.util.concurrent.RecursiveAction;
public class Task extends RecursiveAction {
private List<Product> products;
private int first;
private int last;
public Task(List<Product> products, int first, int last) {
this.products = products;
this.first = first;
this.last = last;
}
@Override
protected void compute() {
if (last - first < 10) {
updatePrices();
} else {
int middle = (last + first) / 2;
System.out.printf("Task: Pending tasks: %s\n", getQueuedTaskCount());
Task t1 = new Task(products, first, middle + 1);
Task t2 = new Task(products, middle + 1, last);
invokeAll(t1, t2);
}
}
private void updatePrices() {
Random random = new Random();
for (int i = first; i < last; i++) {
Product product = products.get(i);
product.setPrice((int) (Math.random() * (21 - 10 + 1) + 10));
}
}
}
public class Product {
private String name;
private int price;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
}
Для относительно небольших задач в конце вычисления будет много потоков, ожидающих на методе join(). Чтоб решить эту проблему, используется класс CountedCompleter<V>. Предположим, что общая задача разбита на дерево подзадач. При разбивке можно указать, на сколько подзадач допустимо разбить текущую задачу или подзадачу. Дочерних задач может быть две, три или больше. Перед завершением метода compute() обязательно должен быть вызван метод tryComplete(). После разбивки известно, сколько для этой задачи или подзадачи образовалось дочерних задач. Допустим, какой-то воркер выполняет подзадачу, у которой нет подзадач. Поток понимает, что дочерних задач нет, и вместо ожидания на методе join() поднимается на задачу выше. Если для родительской задачи выполнены все подзадачи, результаты подзадач собираются вместе. И так происходит до завершения основной задачи. Для более подробного знакомства с классом CountedCompleter следует обратится к документации по Java: https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/CountedCompleter.html
Пример программы использования CountedCompleter приведен в листинге 12.
Листинг 12:
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountedCompleter;
import java.util.concurrent.ForkJoinPool;
public class CountedCompleterExample {
public static void main (String[] args) {
List<BigInteger> list = new ArrayList<>();
for (int i = 3; i < 20; i++) {
list.add(new BigInteger(Integer.toString(i)));
}
ForkJoinPool.commonPool().invoke(
new FactorialTask(null, list));
}
private static class FactorialTask extends CountedCompleter<Void> {
private static int SEQUENTIAL_THRESHOLD = 5;
private List<BigInteger> integerList;
private int numberCalculated;
private FactorialTask (CountedCompleter<Void> parent,
List<BigInteger> integerList) {
super(parent);
this.integerList = integerList;
}
@Override
public void compute () {
if (integerList.size() <= SEQUENTIAL_THRESHOLD) {
showFactorial();
} else {
int middle = integerList.size() / 2;
List<BigInteger> rightList = integerList.subList(middle,
integerList.size());
List<BigInteger> leftList = integerList.subList(0, middle);
addToPendingCount(2);
FactorialTask taskRight = new FactorialTask(this, rightList);
FactorialTask taskLeft = new FactorialTask(this, leftList);
taskLeft.fork();
taskRight.fork();
}
tryComplete();
}
@Override
public void onCompletion (CountedCompleter<?> caller) {
if (caller == this) {
System.out.printf("completed thread : %s numberCalculated=%s%n",
Thread.currentThread().getName(), numberCalculated);
}
}
private void showFactorial () {
for (BigInteger i : integerList) {
BigInteger factorial = calculateFactorial(i);
System.out.printf("%s! = %s, thread = %s%n", i, factorial,
Thread.currentThread().getName());
numberCalculated++;
}
}
private BigInteger calculateFactorial(BigInteger n) {
BigInteger ret = BigInteger.ONE;
for (int i = 1; i <= n; ++i) {
ret = ret.multiply(n);
}
return ret;
}
}
}
В листинге 12 CountedCompleter используется для вычисления факториалов чисел от 3 до 20. Т. к. используется только вычисление факториала и значение не возвращается, класс CountedCompleter типизируется типом Void. Класс FactorialTask переопределяет метод compute() и метод onCompletion(CountedCompleter<?> caller). В конце метода compute() вызывается метод tryComplete() для попытки завершения выполнения задачи, соответственно, должны будут завершиться и подзадачи, если они есть. Метод onCompletion(CountedCompleter<?> caller) вызывается для задачи, которая была выполнена и не была разбита на подзадачи. Такой подход используется в стримах для параллельной обработки данных.











0 комментариев
Добавить комментарий