Java-разработчик Владимир Фролов и Android-разработчик Никита Сизинцев из DataArt, составили краткий курс по многопоточности в Java из шести лекций
5.1 АТОМАРНЫЕ ПЕРЕМЕННЫЕ
Рассмотрим ситуацию, когда два или более потоков пытаются изменить общий разделяемый ресурс: одновременно выполнять операции чтения или записи. Для избежания ситуации race condition нужно использовать synchronized-методы, synchronized-блоки или соответствующие блокировки. Если этого не сделать, разделяемый ресурс будет в неконсистентном состоянии, и значение не будет иметь никакого смысла. Однако использование методов synchronized или synchronized-блоков кода — очень дорогостоящая операция, потому что получение и блокировка потока обходятся недешево. Также этот способ является блокирующим, он сильно уменьшает производительность системы в целом.
Для решения этой проблемы придумали так называемые неблокирующие алгоритмы — non blocking thread safe algorithms. Эти алгоритмы называются compare and swap(CAS) и базируются на том, что современные процессоры поддерживают такие операции на уровне машинных инструкций. С выходом Java 1.5 появились классы атомарных переменных: AtomicInteger AtomicLong, AtomicBoolean, AtomicReference. Они находятся в пакете java.util.concurrent.atomic. Алгоритм compare and swap работает следующим образом: есть ячейка памяти, текущее значение в ней и то значение, которое хотим записать в эту ячейку. Сначала ячейка памяти читается и сохраняется текущее значение, затем прочитанное значение сравнивается с тем, которое уже есть в ячейке памяти, и если значение прочитанное ранее совпадает с текущим, происходит запись нового значения. Следует упомянуть, что значение переменной после чтения может быть изменено другим потоком, потому что CAS не является блокирующей операцией.
5.2 ПРОБЛЕМА ABA ИЛИ LOST UPDATE
Есть два потока. Поток А прочитал значение из памяти, после чего предположим, планировщик потока прервал выполнение потока А. Затем значение из памяти читает поток B, а потом меняет его на ДРУГОЕ несколько раз. Предположим, что изначально значение атомарной переменной было 5, потом 4, в конце оно снова стало равно 5. Получилось так, что поток B в последний раз записал то же значение, что было изначально, т. е. значение, которое было прочитано потоком А. Затем планировщик возобновляет работу потока А, тот сравнивает значение, которое изначально прочитал ( 5) с тем,что есть в памяти сейчас (тоже 5). Эти значения равны — выполняется операция CAS. Возникает такая ситуация, когда новое для системы значение, установленное потоком B (которые, кстати, было равно изначальному значению, которое мы наблюдали до начала работы потоков А и В), затирается старым значением, которое должен был установить поток А. Возникает закономерный вопрос: почему значение теряется? Ведь поток А не записал в память значение, которые он пытался записать, а вот когда планировщик потоков возобновил работу потока А, значение наконец записалось?
Предположим, что ячейка памяти отображает какое-то глобальное состояние системы, или, например,какой-то циклический адрес или повторяющуюся сущность. В этом случае такое поведение просто недопустимо. Решить CAS-проблему может счетчик количества изменений. В первой операции при чтении значения из памяти происходит также чтение счетчика. При выполнении CAS-операции сравнивается значение памяти на текущий момент со старым значением, прочитанным ранее, и производится сравнение текущего значения счетчика со значением счетчика, которое было прочитано на предыдущем шаге. Если в обеих операциях сравнения получен результат true, выполняется CAS-операция и записывается новое значение. Также стоит отметить, что при записи нового значения с помощью CAS-операции значение счетчика увеличивается. Причем значение счетчика увеличивается только при записи!
Возвращаясь к примеру про lost update: когда поток А получит управление и попытается выполнить CAS-операцию, значения памяти будут равны, а значения счетчиков равны не будут. Поэтому поток А опять прочитает значение из памяти и значение счетчика — и опять попытается выполнить CAS-операцию. Это будет происходить до тех пор пока CAS-операция не выполниться успешно. Однако и при использовании счетчика возникают определенные проблемы, рассмотрение которых выходит за рамки нашего цикла статей. На практике сейчас используется алгоритм safe memory reclamation (SMR).
Рассмотрим, как работает класс AtomicLong (Листинги 1, 2 и 3).
Листинг 1: класс AtomicLong:
public final long getAndAdd(long delta) {
return unsafe.getAndAddLong(this, valueOffset, delta);
}
Здесь видно, что выполнение делегируется классу Unsafe.
Листинг 2: класс Unsafe:
public final long getAndAddLong(Object object, long offset, long newValue) {
long oldValue;
do {
oldValue = this.getLongVolatile(object, offset);
} while(!this
.compareAndSwapLong(object, offset, oldValue, oldValue + newValue));
return oldValue;
}
Тут получается старое значение, затем устанавливается новое с помощью операции CAS в том случае, если между чтением и CAS-операцией никакие другие потоки не изменят значение. В противном случае, цикл выполняется, пока это условие не будет соблюдено.
Листинг 3: класс AtomicLong. Получение смещения поля value в объекте AtomicLong.
static {5.3 МНОГОПОТОЧНЫЕ КОЛЛЕКЦИИ
try {
valueOffset = unsafe
.objectFieldOffset(AtomicLong.class.getDeclaredField("value"));
} catch (Exception ex) {
throw new Error(ex);
}
}
Обычные коллекции в Java не синхронизированы и не могут быть безопасно использованы в многопоточной среде. За исключением случаев, когда обращение к этим коллекциям происходит из синхронизированных блоков кода. Неправильное использование коллекций может привести к неконсистентности данных или ConcurrentModificationException.
В Java есть коллекции, которые предназначены для использования в многопоточной среде. Они реализуют разные механизмы синхронизации данных. До выхода Java 1.5 в наличии были следующие многопоточные коллекции: Stack, Vector, HashTable. Все методы этих классов являются synchronized. Это означает, что при вызове любого метода этих классов другой поток будет заблокирован, даже если вызванный метод — метод чтения. Эти коллекции появились еще с версией Java 1 и в современной разработке их не стоит использовать. C выходом Java 1.2 появился утилитный класс Collections, который предоставляет статические методы для оборачивания стандартных коллекций в их синхронизированные представления. Это сделано для совместимости с Java версией 1.
После релиза Java 1.5, 1.6 и 1.7 появилась возможность использовать следующие классы коллекций, которые предназначены и оптимизированы для работы в многопоточной среде:
- CopyOnWriteArrayList <E>
- CopyOnWriteArraySet <E>
- ConcurrentSkipListSet <E>
- ConcurrentHashMap <K, V>
- ConcurrentSkipListMap <K, V>
- ConcurrentLinkedQueue <E>
- ConcurrentLinkedDeque <E>
- ArrayBlockingQueue <E>
- DelayQueue <E extends Delayed>
- LinkedBlockingQueue <E>
- PriorityBlockingQueue <E>
- SynchronousQueue <E>
- LinkedBlockingDeque <E>
- LinkedTransferQueue <E>
Первые две коллекции — copy on write структуры. Третья коллекция — skip list структура. Следующие две коллекции — классы Map, предназначенные для использования в многопоточных программах. Использование классов этих коллекций позволяет увеличить производительность программы по сравнению с использованием устаревших классов из Java 1. Рассмотрим статические методы утилитарного класса Collections.
5.4 СТАТИЧЕСКИЕ МЕТОДЫ ИЗ КЛАССА COLLECTIONS
Статические методы для работы с многопоточностью в классе Collections:
- synchronizedCollection()
- synchronizedList()
- synchronizedMap()
- synchronizedSet()
- synchronizedSortedSet()
- synchronizedSortedMap()
Применяют декоратор к обычной коллекции, который оборачивает каждый метод в synchronized-блок, в результате чего при каждом чтении или изменении обернутой коллекции происходит блокировка всех остальных операций. Т. к. перечисленные методы были добавлены для обратной совместимости, в новых многопоточных программах лучше использовать многопоточные коллекции, которые мы рассмотрим далее.
5.5 COPY ON WRITE СТРУКТУРЫ ДАННЫХ
CopyOnWriteArrayList используется, когда есть много потоков, которые читают элементы из коллекции, и несколько потоков, которые редко записывают данные в коллекцию. Copy on write структура создает новую копию данных при записи в эту структуру. Это позволяет нескольким потокам одновременно читать данные, и одному потоку записывать элементы в коллекцию в каждый конкретный момент времени. Внутри структура данных содержит volatile массив элементов и при КАЖДОМ изменении коллекции: добавлении, удалении или замене элементов, создается новая локальная копия массива для изменений. После модификации измененная копия массива становится текущей. Массив элементов используется с ключевым словом volatile для того, чтобы все потоки сразу увидели изменения в массиве. Такой алгоритм работы с данными гарантирует, что читающие потоки будут читать не изменяющиеся во времени данные, и не будет сгенерирован ConcurrentModificationException при параллельном изменение массива. Если для чтения коллекции используется Iterator, при попытке вызвать remove() при обходе коллекции будет сгенерировано UnsupportedOperationException, потому что текущая копия коллекции не подлежит изменению. Для операций записи внутри класса CopyOnWriteArrayList создается блокировка, чтобы в конкретный момент времени только один поток мог изменять copy on write структуру данных (Листинг 1). Пример добавления элемента представлен в Листинге 4.
Листинг 4:
final ReentrantLock lock = new ReentrantLock();
public boolean add(E e) {
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
Без блокировки наличие нескольких потоков, изменяющих структуру данных, могут привести к потере данных, записываемых потоками. Несколько потоков делают копию исходного массива данных, вносят изменения и записывают их. Какой-то из потоков завершает работу быстрее, какой-то — медленнее. Поток, который завершит свою работу последним, удалит изменения, сделанные другими потоками. С использованием блокировки ReentrantLock такая проблема исчезает. Рассмотрим программу из Листинга 5, которая показывает, что чтение элементов из CopyOnWriteArrayList происходит быстрее, чем чтение из полностью синхронизированной коллекции, либо коллекции, которая обернута соответствующим статическим методом из класса Collections.
Листинг 5:
import java.util.*;
public class PerformanceComparision {
public static void main(String[] args)
throws ExecutionException, InterruptedException {
List<Integer> syncList = Collections.synchronizedList(new ArrayList<>());
List<Integer> cowLst = new CopyOnWriteArrayList<>();
fillLst(syncList);
fillLst(cowLst);
System.out.println("List synchronized:");
checkList(syncList);
System.out.println("CopyOnWriteArrayList:");
checkList(cowLst);
}
private static void fillLst(List<Integer> list) {
IntStream.rangeClosed(1, 100).forEach(list::add);
}
private static void checkList(List<Integer> list)
throws ExecutionException, InterruptedException {
CountDownLatch latch = new CountDownLatch(1);
ExecutorService executors = Executors.newFixedThreadPool(2);
Future<Long> f1 = executors.submit(new ListRunner(latch, 0, 49, list));
Future<Long> f2 = executors.submit(new ListRunner(latch, 50, 99, list));
executors.shutdown();
latch.countDown();
System.out.println("Thread1: " + f1.get()/1000);
System.out.println("Thread2: " + f2.get()/1000);
}
}
public class ListRunner implements Callable<Long> {
private CountDownLatch latch;
private int start;
private int end;
private List<Integer> list;
public ListRunner(CountDownLatch latch, int start, int end, List<Integer> list) {
this.latch = latch;
this.start = start;
this.end = end;
this.list = list;
}
@Override
public Long call() throws Exception {
latch.await();
Integer integer;
long startTime = System.nanoTime();
for (int i = start; i < end; ++i) {
integer = list.get(i);
}
return System.nanoTime() - startTime;
}
}
В программе создается два списка: CopyOnWriteArrayList и обычный ArrayList, который обернут с помощью статического метода Collections.synchronizedList. Т. е. все методы класса будут синхронизированы. Затем каждый список заполняется значениями от 1 до 100. Для рассматриваемой программы неважно, какими конкретно значениями будут заполнены оба списка. Затем создаются два потока, которые одновременно читают один и тот же список. Один поток читает первые 50 элементов в списке, второй поток читает следующие 50. Два потока запускаются одновременно с помощью блокировки CountDownLatch. На консоль выводится время, которое каждый поток потратил на чтение своей половины списка.
Очевидно, что в синхронизированной версии списка только один поток может читать данные в каждый момент времени. И в лучшем случае сначала прочитать значение удастся одному потоку, а только потом это сделает второй. Противоположная ситуация наблюдается при использовании CopyOnWriteArrayList. В этой коллекции несколько потоков могут одновременно читать данные из списка, не блокируя друг друга. Следовательно чтение завершится быстрее, потому что не будет взаимных блокировок.
Copy on write — коллекция, которая не поддерживает дубликаты и хранит элементы в произвольном порядке CopyOnWriteArraySet. Внутри CopyOnWriteArraySet используется CopyOnWriteArrayList, и для него характерны те же свойства.
5.6 SKIP LIST СТРУКТУРА ДАННЫХ
Если необходимо иметь отсортированное множество элементов, следует использовать ConcurrentSkipListSet, который реализует интерфейсы SortedSet и NavigableSet.
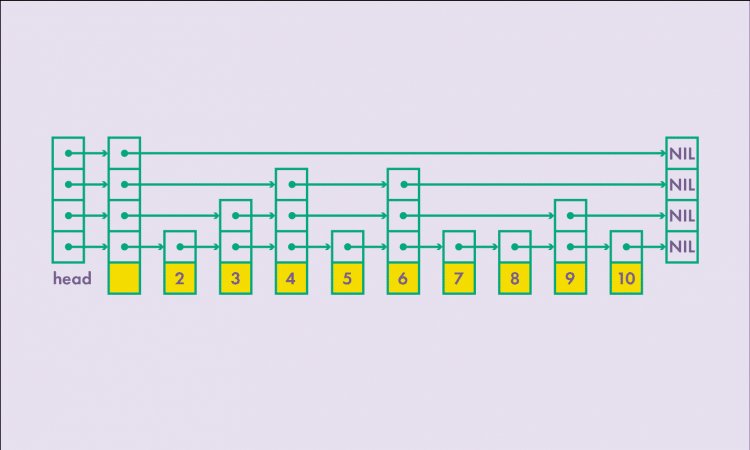
Реализация ConcurrentSkipListSet базируется на ConcurrentSkipListMap, структура ConcurrentSkipListSet похожа на структуру LinkedHashMap. Каждый элемент skip list структуры, кроме значения, содержит ссылку на соседние элементы. Также есть ссылки высших порядков, которые указывают на элементы, находящиеся впереди текущего, на произвольное число в определенном диапазоне, заданном для этого уровня ссылок. Для следующего уровня ссылок это число больше, чем для предыдущего.
Преимущество этой структуры данных — поиск нужного элемента происходит очень быстро за счет использования ссылок высших порядков. Производительность поиска в этой структуре данных сравнима с поиском элементов в бинарном дереве. Для вставки изменения этой структуры данных не нужно полностью блокировать структуру, достаточно найти элемент, который будет удален, и заблокировать два соседних элемента для изменения ссылок, указывающих на элемент, подлежащий изменению.
5.7 ИНТЕРФЕЙС BLOCKINGQUEUE
BlockingQueue — интерфейс потокобезопасных очередей, в которую несколько потоков могут записывать данные и читать их оттуда. Это достигается за счет способности очереди блокировать поток, который добавляет или читает элементы из очереди. Например, когда поток пытается получить элемент из очереди, но очередь пустая — поток блокируется. Или когда поток пытается положить объект в очередь, которая уже заполнена, поток тоже блокируется.
Блокирующие очереди используются, когда одни потоки добавляют элементы в очередь, а другие читают их оттуда. Этот паттерн известен как producer consumer. Потоки, которые добавляют объекты в очередь, называются producer (Производитель). Добавлять элементы в очередь можно до тех пор, пока она не заполнится. Потоки которые читают значения, называются consumer (Потребитель). Читать из очереди можно только в случаях, когда в ней есть элементы.
BlockingQueue хранит свои элементы по принципу FIFO. Элементы отсортированы по времени нахождения в очереди, а голова находится там дольше всех остальных.
BlockingQueue не поддерживает значение null, при попытке вставить его генерируется NullPointerException.
Интерфейс BlockingQueue поддерживает четыре наборов методов, которые поддерживают разное поведение при добавлении или получении элементов из очереди.
Генерация исключения | Специальное значение | Блокирование потока | Тайм аут | |
Добавление | add(o) | offer(o) | put(o) | offer(o, timeout) |
Удаление | remove(o) | poll() | take() | poll(timeout) |
Проверка | element() | peek() |
Четыре типа поведения означают следующее:
- Если немедленное выполнение операции невозможно, генерируется исключение.
- Если немедленное выполнение операции невозможно, возвращается значение — в основном true или false.
- Если немедленное выполнение операции невозможно, то поток, выполняющий эту операцию блокируется.
- Если операция не может быть выполнена немедленно, поток, вызвавший этот метод, блокируется не больше чем на время, указанное в метоти методы в зависимости от успеха окончания возвращают true или false.
Классы, которые реализуют интерфейс BlockingQueue: ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue, PriopityBlockingQueue, SynchronousQueue.
Очередь ArrayBlockingQueue имеет конечный размер. Элементы в этой очереди хранятся в массиве. Количество элементов в очереди задается в конструкторе и не может быть изменено после ее создания.
DelayQueue — очередь с задержкой. Когда поток хочет получить элемент из очереди, элемент возвращается, после того как задержка для конкретного элемента истекла. Каждый элемент, который будет помещен в очередь DelayQueue, должен реализовывать интерфейс Delayed, где есть единственный метод long getDelay(). Этот метод должен возвращать оставшееся время задержки для этого элемента в правильных единицах TimeUnit. Когда вызывается метод получения элемента из очереди, DelayQueue вызывает метод getDelay() для определения, какой элемент должен быть возвращен из очереди. Если этот метод вернул значение, близкое к нулю, ноль или отрицательное значение, этот элемент может быть возвращен из очереди. Также элемент, который должен помещаться в DelayQueue, должен реализовать метод compareTo(), потому что элементы в очереди сортируются. Элемент, время задержки которого истечет быстрее всего, помещается в голову очереди.
В DelayQueue можно помещать элементы, для которых вызов метода getDelay() возвращает нулевое или отрицательное число. Поток, который читает элементы из очереди, получит этот элемент немедленно. Пример программы с использованием DelayQueue представлен в Листинге 6.
Листинг 6:
import com.google.common.primitives.Ints;
public class DelayObject implements Delayed {
private String data;
private long startTime;
public DelayObject(String data, long delayInMilliseconds) {
this.data = data;
this.startTime = System.currentTimeMillis() + delayInMilliseconds;
}
@Override
public long getDelay(TimeUnit unit) {
long diff = startTime - System.currentTimeMillis();
return unit.convert(diff, TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
return Ints.saturatedCast(this.startTime - ((DelayObject) o).startTime);
}
}
public class DelayQueueProducer implements Runnable {
private BlockingQueue<DelayObject> queue;
private Integer numberOfElementsToProduce;
private Integer delayOfEachProducedMessageMilliseconds;
public DelayQueueProducer(BlockingQueue<DelayObject> queue,
Integer numberOfElementsToProduce,
Integer delayOfEachProducedMessageMilliseconds) {
this.queue = queue;
this.numberOfElementsToProduce = numberOfElementsToProduce;
this.delayOfEachProducedMessageMilliseconds =
delayOfEachProducedMessageMilliseconds;
}
@Override
public void run() {
for (int i = 0; i < numberOfElementsToProduce; i++) {
DelayObject object = new DelayObject(UUID.randomUUID().toString(),
delayOfEachProducedMessageMilliseconds);
System.out.println("Put object: " + object);
try {
queue.put(object);
Thread.sleep(500);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}
public class DelayQueueConsumer implements Runnable {
private BlockingQueue<DelayObject> queue;
private Integer numberOfElementsToTake;
public AtomicInteger numberOfConsumedElements = new AtomicInteger();
public DelayQueueConsumer(BlockingQueue<DelayObject> queue,
Integer numberOfElementsToTake) {
this.queue = queue;
this.numberOfElementsToTake = numberOfElementsToTake;
}
@Override
public void run() {
for (int i = 0; i < numberOfElementsToTake; i++) {
try {
DelayObject object = queue.take();
numberOfConsumedElements.incrementAndGet();
System.out.println("Consumer take: " + object);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class TestDelayQueue {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
BlockingQueue<DelayObject> queue = new DelayQueue<>();
int numberOfElementsToProduce = 2;
int delayOfEachProducedMessageMilliseconds = 500;
DelayQueueConsumer consumer = new DelayQueueConsumer(
queue, numberOfElementsToProduce);
DelayQueueProducer producer = new DelayQueueProducer(
queue, numberOfElementsToProduce,
delayOfEachProducedMessageMilliseconds);
executor.submit(producer);
executor.submit(consumer);
executor.awaitTermination(5, TimeUnit.SECONDS);
executor.shutdown();
System.out.println(“Is number of consumed elements equal
to number of produced elements? ” +
consumer.numberOfConsumedElements.get() ==
numberOfElementsToProduce);
}
}
Класс PriorityBlockingQueue — безразмерная очередь. Все элементы, которые вставляются в PriorityBlockingQueue, должны реализовывать интерфейс java.lang.Comparable или допускать сортировку по natural ordering. Итератор, полученный для этой коллекции, не гарантирует итерацию по элементам в порядке приоритета. Если элементы, которые будут добавляться в очередь, не реализуют интерфейс Comparable, можно передать компаратор при создании объекта PriorityBlockingQueue.
Класс SynchronousQueue для добавления элемента в очередь вызывает метод put(). При вызове этого метода вызывающий поток блокируется, пока другой поток не вызовет метод take(). Также класс SynchronousQueue можно представить как точку синхронизации между двумя потоками, когда один поток дает элемент, а второй его получает. Также про SynchronousQueue говорят, что это очередь без единого элемента.
Т. к. SynchronousQueue — очередь без элементов, эта коллекция ведет себя специфически: метод isEmpty() всегда возвращает true, метод iterator() возвращает пустой итератор, метод hasNext() всегда возвращает false,
peek() всегда возвращает null, size() всегда возвращает 0.
Пример использования SynchronousQueue в качестве producer consumer представлен в Листинге 7.
Листинг 7:
import java.util.Random;
import java.util.concurrent.*;
public class SynchQueue {
public static void main(String[] args) {
BlockingQueue<Integer> syncQueue = new SynchronousQueue<>();
Producer producer = new Producer(syncQueue);
producer.start();
Consumer consumer = new Consumer(syncQueue);
consumer.start();
}
}
class Producer extends Thread {
private BlockingQueue<Integer> queue;
public Producer(BlockingQueue<Integer> queue) {
this.queue = queue;
}
public void run() {
while (true) {
try {
queue.put(produce());
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}private Integer produce() {
Random randomer = new Random();
Integer number = randomer.nextInt(1000);
try {
Thread.sleep(randomer.nextInt(1000));
} catch (InterruptedException ie) {
ie.printStackTrace();
}
System.out.println("Producer: created number: " + number);
return number;
}
}
class Consumer extends Thread {
private BlockingQueue<Integer> queue;
public Consumer(BlockingQueue<Integer> queue) {
this.queue = queue;
}
public void run() {
while (true) {
try {
System.out.println("Consumed number = " + queue.take());
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
}
В этой программе producer генерирует произвольные числа, а consumer выводит эти числа на экран. Сгенерировав произвольное число, поток
producer засыпает его на произвольное время. В это время поток consumer находится в состоянии WAITING. После того как объект помещен в SynchronousQueue, поток consumer просыпается и выводит на консоль полученное значение. Поток producer в это непродолжительное время находится в состоянии WAITING. И так будет продолжаться бесконечно, пока программу не остановят.
МНОГОПОТОЧНЫЕ РЕАЛИЗАЦИИ ИНТЕРФЕЙСА MAP
Есть три реализации интерфейса Map для работы в многопоточных коллекциях: HashTable, ConcurrentHashMap и ConcurrentSkipListMap. В классе HashTable все методы являются synchronized, и эту структуру данных можно использовать в многопоточных программах. Однако этот класс уже устарел, и его использование не рекомендуется. При операции чтения или записи блокируются все остальные потоки, которые хотят либо изменить, либо прочитать эту структуру данных. Очевидно, что производительность HashTable очень низкая. В современных программах в критических секциях рекомендуется использовать ConcurrentHashMap или ConcurrentSkipListMap. Рассмотрим работу этих классов подробнее.
ConcurrentHashMap. Прежде всего, обратимся к структуре класса HashMap. Есть массив бакетов, внутри каждого из которых находится либо связанный список, либо бинарное дерево. Внутри ConcurrentHashMap состоит из массива сегментов, каждый из которых содержит отдельную HashMap с массивом бакетов.
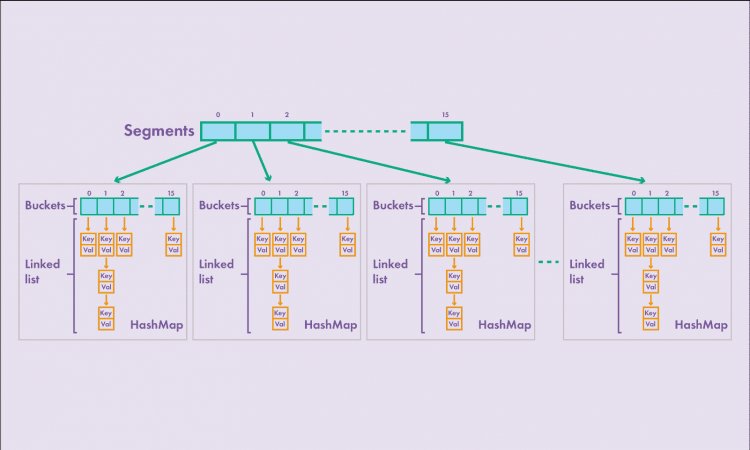
При добавлении пары «ключ—значение» в такую структуру данных происходит блокировка отдельного сегмента, а после добавления пары «ключ—значение» все происходит, как в обычной карте. Если происходит чтение, сегмент не блокируется, и несколько потоков могут читать данные одновременно. Операции изменения карты могут происходить одновременно в том случае, когда потоки обращаются к разным сегментам. Два потока не могут одновременно изменять один и тот же сегмент. Однако один поток может производить изменения в сегменте, а другой поток может параллельно этот сегмент читать этот же сегмент. Это возможно благодаря тому, что при чтении данных сегмент не блокируется. При одновременном чтении и модификации данных в результате чтения вернется последнее измененное значение. В ConcurrentHashMap для каждого сегмента есть своя собственная блокировка. По умолчанию, количество сегментов равно 16. Количество сегментов рассчитывается на основании параметра int concurrencyLevel. Это дополнительный параметр, который можно передать в конструктор при создании класса. Количество сегментов по умолчанию означает, что в карту могут записывать 16 потоков. Количество сегментов рассчитывается на основании concurrencyLevel. Число два возводится в степень начиная от 1, причем результат должен быть больше, либо равен параметру concurrencyLevel. Например:
Количество сегментов = 2 ^ 1 = 2 >= 10 (False)
Количество сегментов = 2 ^ 2 = 4 >= 10 (False)
Количество сегментов = 2 ^ 3 = 8 >= 10 (False)
Количество сегментов = 2 ^ 4 = 16 >= 10 (True)
При concurrencyLevel равном 10 количество сегментов 16. Количество бакетов в каждом сегменте рассчитывается по следующей формуле:
2^x >= (initialCapacity/concurrencyLevel), где за X будет принято количество бакетов в сегменте.
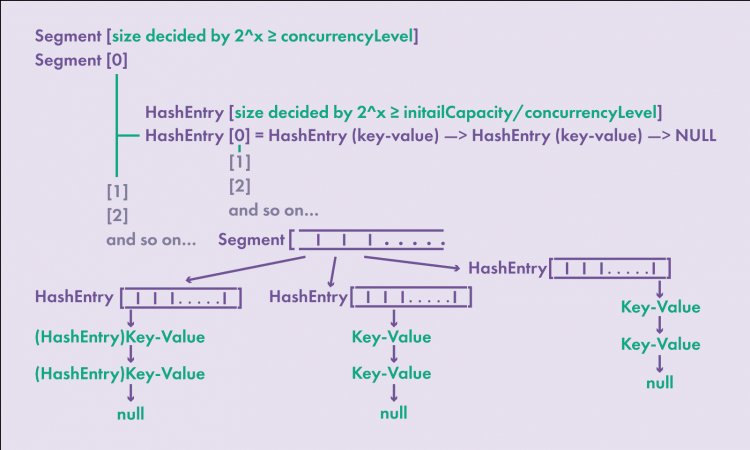
Рехеширование в ConcurrentHashMap происходит по отдельности в каждом сегменте, поэтому оно может выполняться одновременно с записью в другой сегмент.
ConcurrentSkipListMap. Этот класс использует принцип skipList, который рассмотрен ранее. ConcurrentSkipListMap сортирует ключи в соответствии с natural sortлиng или с логикой компаратора, который передается конструктору. Класс реализует интерфейсы SortedMap, NavigableMap, ConcurrentMap, ConcurrentNavigableMap. ConcurrentSkipListMap гарантирует выполнение всех основных операций за O(log(n)).
ConcurrentSkipListMap поддерживает методы навигации lowerEntry, floorEntry, ceilingEntry, и higherEntry, которые возвращают объекты Map.Entry «меньше чем», «меньше или равно», «больше или равно» и «больше чем» переданный ключ. Методы lowerKey, floorKey, ceilingKey и higherKey возвращают только ключи. ConcurrentSkipListMap не поддерживает null значения ни в ключах, ни в значениях.











0 комментариев
Добавить комментарий