Мене звати Олександр, і я вже 10 років намагаюся робити DevOps. Зараз я працюю Tech Lead в Coherent Solutions / ISsoft. У цій статті я хотів би висвітлити best practices того, як варто працювати з Kubernetes.
Не будемо зупинятися на технічних деталях K8s. Ця стаття – про поширені проблеми, які можуть виникати у процесі роботи. Пройшовши «вогонь, воду та мідні труби» з Kubernetes, мені справді є чим поділитися і що порадити хлопцям, які хочуть розвиватися у цій галузі. Ця інформація буде корисною всім, хто цікавиться DevOps і хоч раз мав справу з оркестрацією контейнерів.

Грунтуючись на багаторічний досвід, спільно з моїм колегою виділили кілька поганих і добрих порад для побудови мікросервісних рішень. Ми постаралися зібрати патерни, які можуть допомогти вам налаштувати та успішно підтримувати ваш environment.
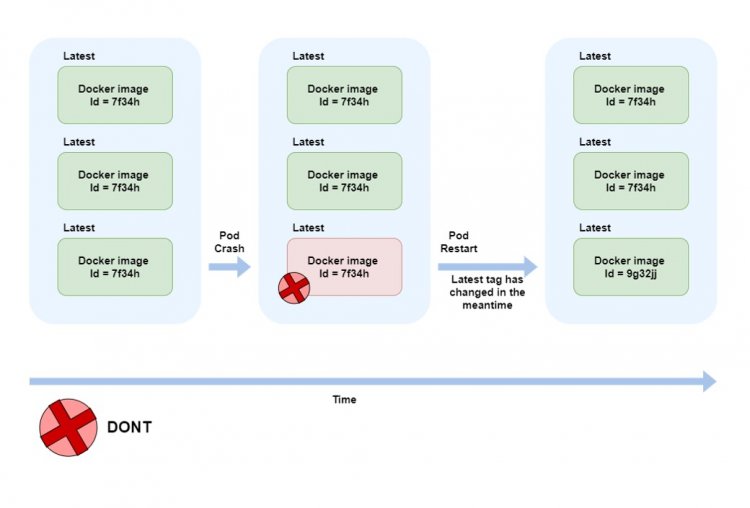
1. Використання контейнерів з тегом latest у розгортанні Kubernetes.
Це зустрічається повсюди: як на співбесіді, так і в роботі - використання правильних тегів для докеру образів. Latest - на перший погляд нешкідливий тег, який бере останній реліз того чи іншого продукту, який ви хочете завантажити. У мене одного разу стався неприємний досвід його використання, коли я працював на одному із проектів. За своєю дурістю і недалекоглядністю вирішив використовувати latest тег і одного разу у мене перестав працювати monitoring. Коли я залишився без метрик та графіків, треба було розбиратися через невдалий деплой. У github у розробника побачив, що в тому самому репозиторії було залінковано кілька продуктів. Під тегом latest на момент deploy'a у репозиторії висів інший продукт. І якщо я використав перший, то за тегом latest на той момент вже був другий. У цій ситуації я отримав неправильний продукт, який не дозволив мені працювати далі. Не раджу використовувати цей тег, а замість нього можу запропонувати наступне:
Використовувати теги з хешами Git (наприклад, docker.io/myusername/my-app:acef3e). Це просто реалізувати, але може бути зайвим, оскільки хеш Git нелегко сприймається не технічними фахівцями.
Використовувати теги з версією програми, що йдуть за семантичними версіями (наприклад, docker.io/myusername/my-app:v1.0.1).
Використовувати теги, які позначають послідовне число, наприклад номер складання або дату/час складання. З цим форматом складно працювати, але його можна легко застосувати у застарілих програмах. Також можна додати короткий хеш комміту. Це може в майбутньому допомогти швидко знайти потрібну помилку в одному з релізів.
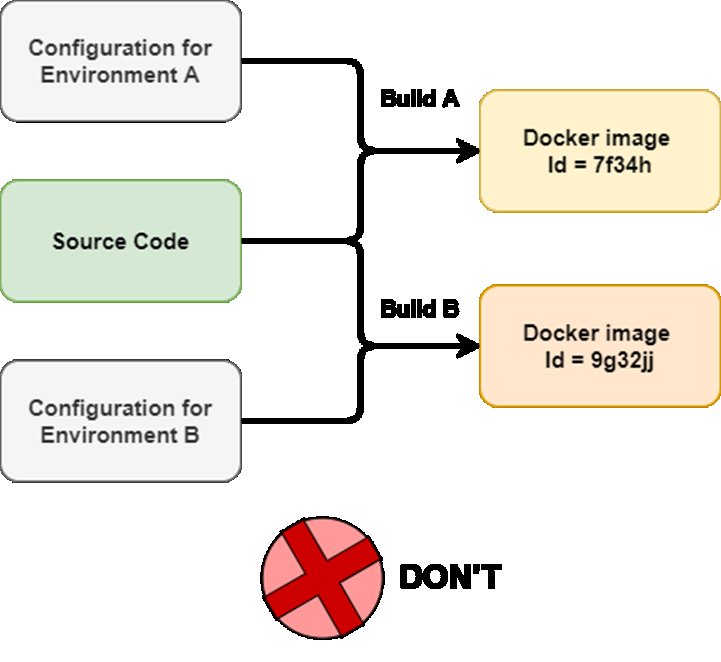
2. Запікання конфігурації всередині контейнера та образу.
Іноді можна зіштовхнутись із ситуацією, коли ми запікаємо налаштування певного environment'у всередину контейнера. Виправдовується це тим, що все знаходиться в одному місці, і це спрощує роботу. Однак конфігурація та образи можуть дуже швидко змінюватися під час розробки. У цій ситуації нам потрібно все збирати наново. Враховуючи те, що ми оптимізуємо і намагаємося прискорити процеси, такий варіант зовсім не підходить. Якщо ми хочемо дотримуватись хороших DevOps практик, нам треба тестувати одну версію зібраного продукту на всіх environment'ах. З таким підходом ви цього не зможете зробити.
Натомість раджу вам створювати універсальні образи контейнерів, які нічого не знають про середовище, в якому вони працюють.
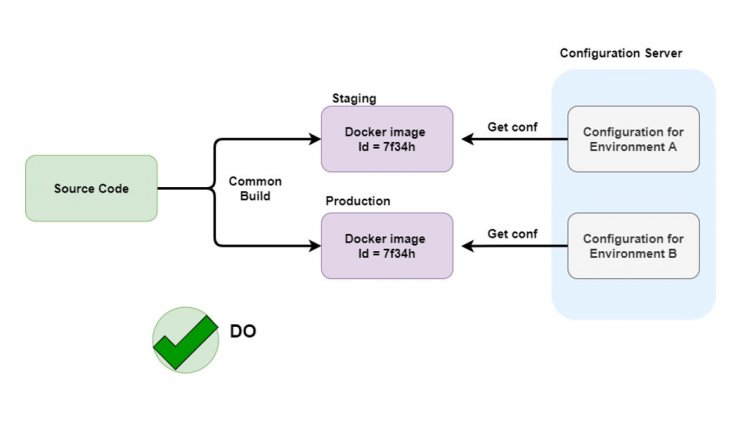
Цим можна скористатися під час роботи не лише з налаштуваннями environment'у, а й із secret'ами.
3. Правильна стратегія роботи із secret'ами.
До поширених небажаних патернів можна віднести:
Використання кількох способів для роботи із secret'ами.
Не найкращий сценарій, коли програма йде в vault і забирає звідти секрет.
Плутанина між runtime та build secret’ами.
Використання складних механізмів введення secret'ів, які ускладнюють або унеможливлюють локальну розробку та тестування.
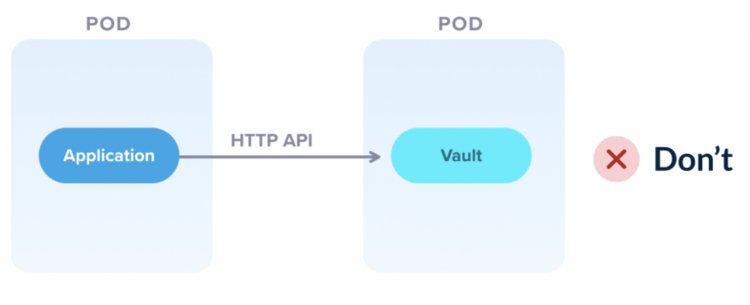
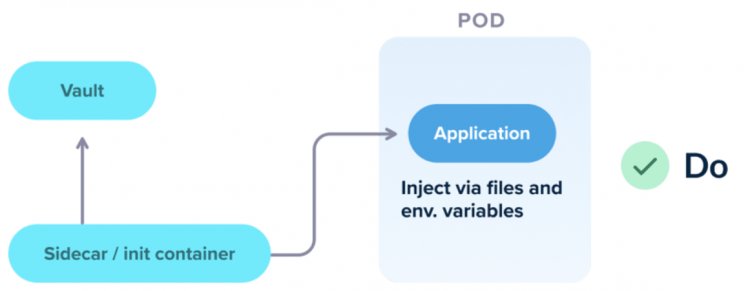
Вдалою стратегією є використання якоїсь додаткової програми, яка йде в vault і дає POD ту конфігурацію секретних даних, яку вона шукає. Саме такий підхід вважаю правильним, оскільки POD та додаток у якомусь оточенні не повинні знати де вони працюють і де щось розташоване. Коректна побудова відносин між додатком та сервісами передбачає, що всі необхідні маніпуляції відбуваються за зовнішніми запитами, а не внутрішніми.
З практики можу навести приклад, коли з командою робили щось схоже в Azure AKS і сам Microsoft писав рекомендацію, що потрібно використовувати певні програми, які йдуть в Azure Key Vault, щоб звідти брати secret'и та пушити в POD. Вона, у свою чергу, приймала дані і використовувала в runtime не зберігаючи. Коли POD створюється заново, вона не має жодних закріплених secret'ів, які можуть бути скомпрометовані.
4. Розгортання програм у поєднанні з розгортанням інфраструктури.
Хотілося б приділити увагу важливій agile-практиці CI/CD, коли розробник deploy'ить його додаток та поєднує розгортання інфраструктури з розгортанням програми. Важливо розуміти коли це може бути добре, а коли небажано. Якщо ми говоримо про Kubernetes, то підняти новий namespace з deployment'ом програми не буде проблемою, а наприклад, якісь мережеві частини environment'ів у хмарі можуть затягуватися: від 10 до 20 хвилин, замість 2–3. Це значно впливає на вашу особисту ефективність та продуктивність команди.
Важливо не виконувати роботу заради роботи.
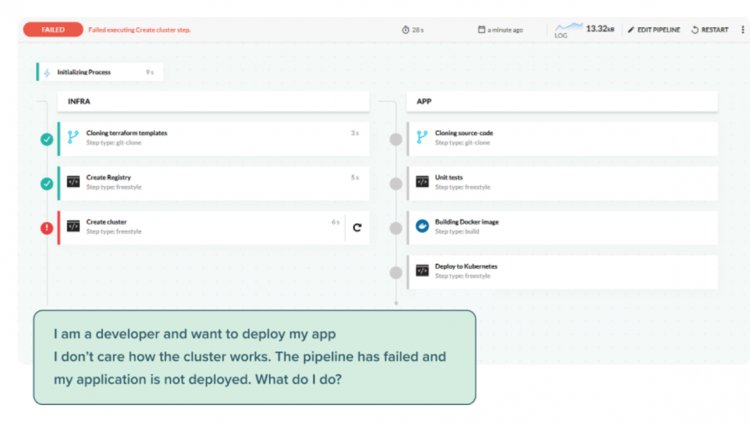
5. Deploy ad-hoc за допомогою kubectl edit/patch вручну.
Тут йтиметься більше про підхід загалом. Змоделюємо ситуацію: розробнику чи тестувальнику дають адміністративний доступ до додатку. Конфігураційний дрифт накопичується після того, як він щось змінює вручну.
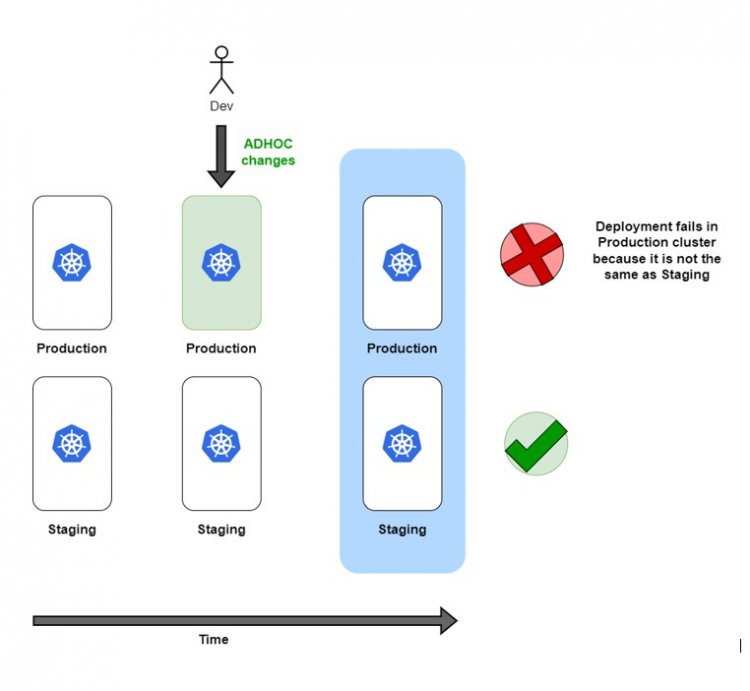
Configuration drift – широко відома проблема, що існувала ще до появи Kubernetes. Вона виникає, коли два чи більше середовища вважаються однаковими, але після певних розгортань чи змін вони перестають мати однакову конфігурацію. Можливості kubectl з виправлення/редагування слід використовувати лише для експериментів. Зміна реальних ресурсів на Production кластері вручну – це катастрофа. Крім правильного робочого процесу розгортання, варто чітко розуміти, що зловживати kubectl не можна.
6. Опис програми в одному файлі.
У цьому патерні сфокусуємося на розгортанні і як вони можуть впливати на ваш кластер. Найкласніший приклад у даному контексті – deploy без лімітів СPU/RAM. Коли ви працюєте з безліччю програм, таких як Java додатки, вони можуть поглинати занадто багато ресурсів. Причому це не залежить від Java, тут немає претензії до мови програмування. На жаль, не всі розуміють, як працює garbage collector і, як правило, більшість ресурсів йдуть туди, в той час як нашим завданням залишається мінімізувати ризики. Для тих, хто не працював з лімітами СPU/RAM, поясню чим це загрожує: ваш додаток просто не запуститься.
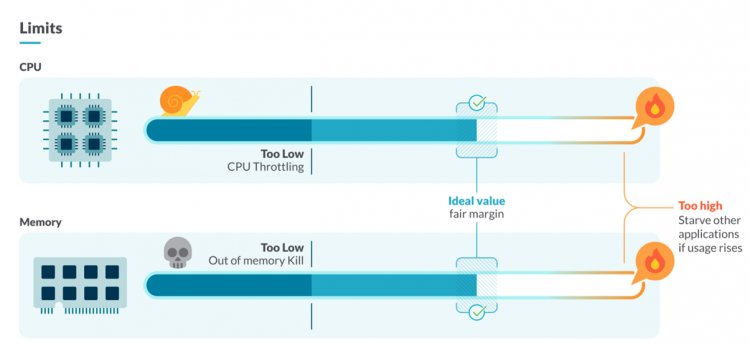
Вам також необхідно вивчити мови програмування щодо специфічних моделей використання і того, як ресурси використовуються основною платформою. Наприклад, застарілі Java програми мають сумно відомі проблеми з лімітами пам'яті.
Як знайти відповідний ліміт СPU/RAM:
Conservative
max by (namespace,owner_name,container)((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))
max by (namespace,owner_name,container)((container_memory_usage_bytes{container!="POD",container!=""}) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))
Aggressive
quantile by (namespace,owner_name,container)(0.99,(rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))
quantile by (namespace,owner_name,container)(0.99,(container_memory_usage_bytes{container!="POD",container!=""}) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))
7. Правильне використання probe у deployment'ах.
Якщо ви ще не використовуєте health probe, саме час почати! Це може чудово полегшити вам життя. Давайте розглянемо приклад того, як Probes можуть вплинути на роботу всього environment'a.
Уявіть собі, що не працює сервіс авторизації, який не дозволяє працювати з додатками. За умови, що такий сервіс для декількох програм не працює, весь environment буде вважатися неробочим, оскільки програми не зможуть авторизуватися.
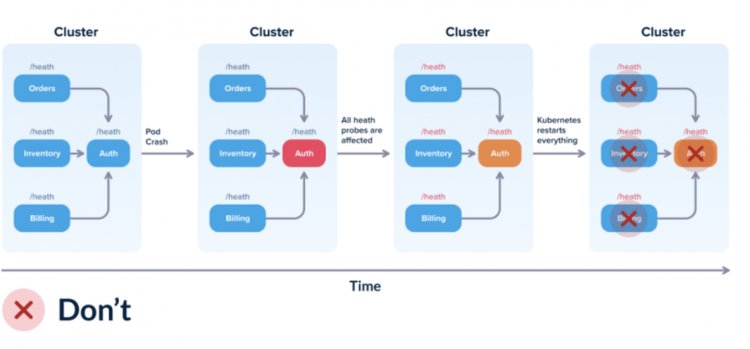
Ось що я рекомендую використовувати для уникнення проблем з додатками:
Startup probe => Перевіряє, чи запустилися ваші програми.
Readiness probe => Перевіряє, чи може ваша програма відповідати зовнішнім запитам. Запускається постійно. У разі невдачі Kubernetes припинить перенаправлення трафіку на вашу програму і спробуйте зробити це пізніше.
Liveness probe => Перевіряє, чи знаходиться ваш додаток у робочому стані. Виконується постійно. У разі невдачі Kubernetes припустить, що ваша програма не працює і перестворить контейнер.
Ми описали лише деякі патерни, які могли б зберегти ваші ресурси, час та гроші. А точніше:
Як правильно використовувати тег latest.
Чому потрібно працювати з універсальними образами контейнерів?
Як утримувати в цілості та безпеці secret'и.
Переваги поетапного розгортання.
Configuration drift та можливості kubectl.
Ліміти CPU/RAM стадії deploy.
Які health probe використати і для чого.
Будемо раді дізнатися про вашу думку з приводу даної тематики в коментарях під даною публікацією.











0 комментариев
Добавить комментарий