Ви пропустили лекцію і попросили зошит у однокурсника, щоб надолужити матеріал. Але переписувати довгий конспект немає ні часу, ні бажання - що ж робити?
Знадобиться додаток, що розпізнає текст в нетекстових документах. На щастя, така технологія існує і називається OCR ( Optical Character Recognition) . Більш того, вона доступна навіть на JavaScript.
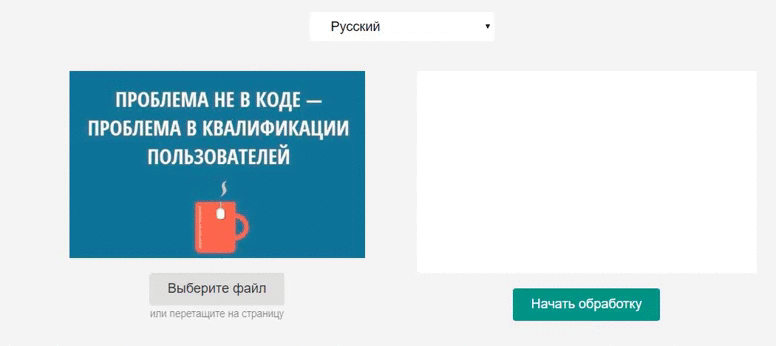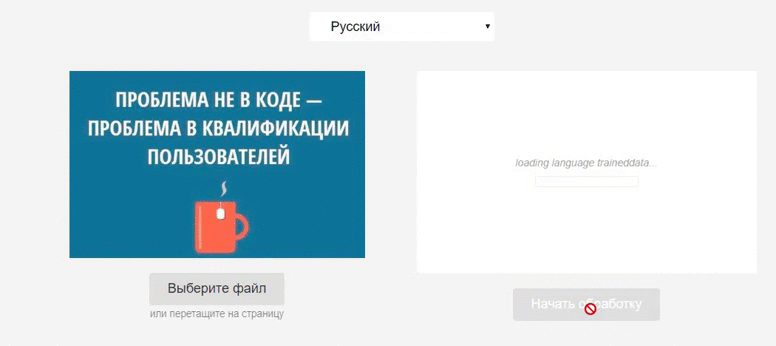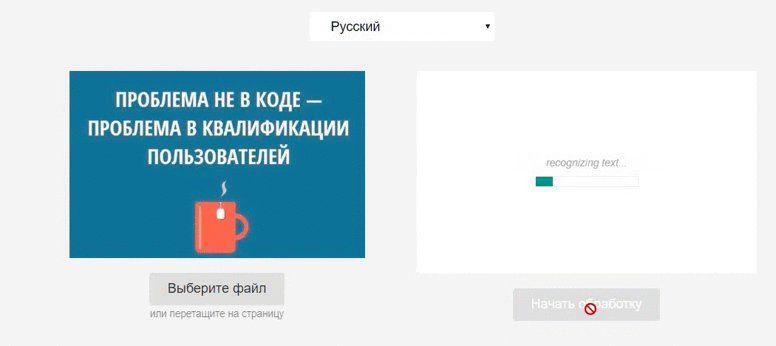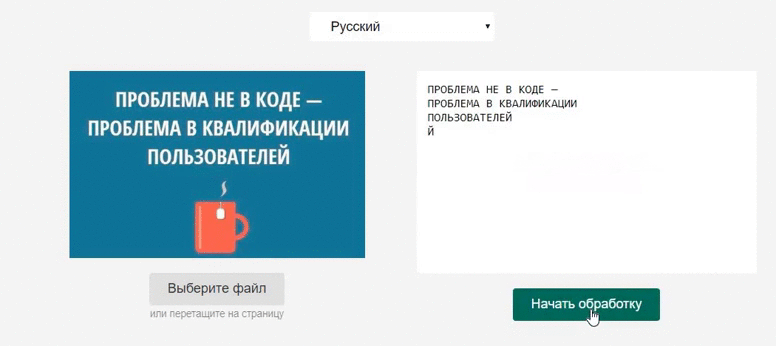
Витяг тексту з зображення за допомогою бібліотеки Tesseract.js
Зустрічайте Tesseract.js - потужну бібліотеку, яка вміє розпізнавати символи на будь-якому зображенні. Сьогодні ми розберемося, як з нею працювати.
1. Підключаємо Tesseract.js
Tesseract.js - це звичайна JavaScript-бібліотека. Щоб використовувати її можливості в проекті, необхідно підключити потрібний файл. Зробити це можна будь-яким зручним способом, наприклад, використовуючи CDN ( https://unpkg.com/tesseract.js@v2.0.0-alpha.13/dist/tesseract.min.js ) або у вигляді npm-пакета:
// через npm
npm install tesseract.js
// через yarn
yarn add tesseract.js
2. Готуємо розмітку
Згідно з офіційним сайтом Tesseract.js підтримує більше 100 мов, в тому числі і українську - для демонстрації можливостей додамо в додаток вибір мови. Ще нам буде потрібно input для завантаження самого зображення і поле для виведення результатів обробки.
Найпростіша розмітка виглядає так:
<! - селект для вибору мови ->
< Select id = " langs " >
< Option value = " uа " selected > Українська </ option >
< Option value = " eng " > English </ option >
</ Select >
<! - інпут для завантаження файлу зображення ->
< Input type = " file " id = " file " />
<! - лог процесу обробки і відображення результату ->
< Div id = " log " > </ div >
<! - кнопка Почати обробку ->
< Button type = " button " id = " start " > Почати обробку </ button >
3. Запускаємо Tesseract
3.1. Worker
Всю роботу виконує воркер TesseractWorker, тому імпортуємо з пакета tesseract.js функцію createWorker. При створенні воркера можна передати функцію логування, викликану при переході між етапами обробки.
import { createWorker } from 'tesseract.js';
const worker = createWorker({
logger: (data) => console.log(data)
});
Вхідний в логгер об'єкт даних містить два поля: status і progress - їх можна використовувати для відображення прогресу обробки.

Логування процесу обробки зображення
Ініціалізуємо воркер з потрібними настройками мови і запускаємо процес розпізнавання:
async function recognize() {
const file = document.getElementById('file').files[0];
const lang = document.getElementById('langs').value;
await worker.load();
await worker.loadLanguage(lang);
await worker.initialize(lang);
const { data: { text } } = await worker.recognize(file);
console.log(text);
await worker.terminate();
return text;
}
3.2. Метод recognize
Те ж саме можна зробити більш декларативно - за допомогою методу recognize об'єкта Tesseract:
import Tesseract from 'tesseract.js';
function recognize() {
const file = document.getElementById('file').files[0];
const lang = document.getElementById('langs').value;
return Tesseract.recognize(file, lang, {
logger: data => console.log(data),
})
.then(({ data: {text }}) => {
console.log(text);
return text;
})
}
Цей метод приймає файл, мову і об'єкт налаштувань з логгером. Метод працює асинхронно і повертає звичайний Promise.
4. Відображення прогресу і результату
В результаті виконання методу recognize ми отримуємо багато корисних даних:

Результат роботи методу recognize
Тут не тільки витягнутий текст, але і рівень впевненості (confidence), і навіть розташування на зображенні символів, слів, абзаців.
Залишилося продемонструвати отримані результати користувачеві.
const log = document.getElementById('log');
// прогрес обробки
function updateProgress(status, progressValue) {
log.innerHTML = '';
const statusText = document.createTextNode(status);
const progress = document.createElement('progress');
progress.max = 1;
progress.value = progressValue;
log.appendChild(statusText);
log.appendChild(progress);
}
// Вивід результату
function setResult(text) {
log.innerHTML = '';
text = text.replace(/\n\s*\n/g, '\n');
const pre = document.createElement('pre');
pre.innerHTML = text;
log.appendChild(pre);
}
Нарешті, додамо обробник кліків на кнопку "почати обробку" і зберемо все разом:
import Tesseract from 'tesseract.js';
// Розпізнавання зображення
function recognize(file, lang, logger) {
return Tesseract.recognize(file, lang, {logger})
.then(({ data: {text }}) => {
return text;
})
}
const log = document.getElementById('log');
// прогрес обробки
function updateProgress(data) {
log.innerHTML = '';
const statusText = document.createTextNode(data.status);
const progress = document.createElement('progress');
progress.max = 1;
progress.value = data.progress;
log.appendChild(statusText);
log.appendChild(progress);
}
// Вивід результату
function setResult(text) {
log.innerHTML = '';
text = text.replace(/\n\s*\n/g, '\n');
const pre = document.createElement('pre');
pre.innerHTML = text;
log.appendChild(pre);
}
document.get ElementById('start').addEventListener('click', () => {
const file = document.getElementById('file').files[0];
if (!file) return;
const lang = document.getElementById('langs').value;
recognize(file, lang, updateProgress)
.then(setResult);
});
Ось і вся програма! Експериментуйте з різними зображеннями і мовами.
Tesseract.js - відмінна JS-бібліотека для розпізнавання тексту з зображень. Звичайно, її можливості сильно обмежені. Зашумлений фон і нестандартні шрифти істотно знижують точність обробки. Однак для багатьох проектів вона може стати чудовим рішенням.











0 комментариев
Добавить комментарий