Список безкоштовних інструментів і бібліотек для аналітиків даних. Заслуговують на увагу пакети, програми та ресурси, про які не так часто згадують, як про NumPy, Pandas або Jupyter.
Нижче представлений стислий огляд 25 інструментів для найрізноманітніших задач науки про дані. Швидкий скрапінг веб-сторінок і візуалізація, аналіз поведінки клієнтів і безпечне зберігання ключів, робота в команді і розгортання моделей на хмарних GPU.
Огляд DS інструментів:
- Airtable: електронна таблиця з потужністю бази даних, альтернатива Google Sheets або Microsoft Excel. Відмінно працює з Pandas, завдяки Python API. Те що потрібно для демонстрації результатів.
- Orange: open source платформа, заточена під машинне навчання і візуалізацію даних, для якої не потрібно вміти кодувати. Якісна альтернатива Tableau або Power BI.
- MarkDown: додаток для нотаток на Node.js, повноцінно працює в офлайні з можливістю розміщення на своєму сервері.
- Deepnote: додаток на базі Jupyter Notebook, створений для спільної роботи в реальному часі.
- Dash by Plotly: JavaScript інструмент візуалізації даних з відкритим вихідним кодом. Запустіть готову модель на Python або R, а Dash подбає про решту. Ідеально підходить для створення дрібних веб-додатків для показу клієнтові.
- KeeWeb: засіб для безпечного зберігання API-ключів і паролів.
- MLxtend (скор. Від Machine Learning Extensions) - бібліотека Python інструментів для повсякденних завдань обробки даних. Творець - автор книги «Машинне навчання на Python» Себастьян Рашка.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import EnsembleVoteClassifier
from mlxtend.data import iris_data
from mlxtend.plotting import plot_decision_regions
# Initializing Classifiers
clf1 = LogisticRegression(random_state=0)
clf2 = RandomForestClassifier(random_state=0)
clf3 = SVC(random_state=0, probability=True)
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3],
weights=[2, 1, 1], voting='soft')
# Loading some example data
X, y = iris_data()
X = X[:,[0, 2]]
# Plotting Decision Regions
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10, 8))
labels = ['Logistic Regression', 'Random Forest',
'RBF kernel SVM', 'Ensemble']
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
labels,
itertools.product([0, 1],
repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y,
clf=clf, legend=2)
plt.title(lab)
plt.show()
- Lifetimes: бібліотека для аналізу поведінки клієнтів, прогнозування прибутку і відтоку
- GitLab: альтернативне GitHub сховище репозиторіїв з можливістю приховувати групові репозиторії. Зручно для закритої командної роботи і групової участі в ML-змаганнях.
- Draw.io: створення діаграм для планування проекту.
- Spider: простий скраппер для веб-сторінок у вигляді розширення Chrome. Можна завантажувати сторінки в CSV / JSON форматі.
- Simple Scraper : перетворить будь-який сайт в API.
- Airbnb Knowledge repo: ресурс для обміну знаннями між фахівцями в області обробки даних та інших технічних професій. Був створений для вирішення проблеми поширення знань в рамках зростаючої команди.
- Kyso : сервіс допомагає створити привабливе і структуроване портфоліо аналітика даних. Ви зможете переглядати чужі портфоліо, побачите, як інші уявляють себе і свої дані. Безкоштовний період 14 днів.
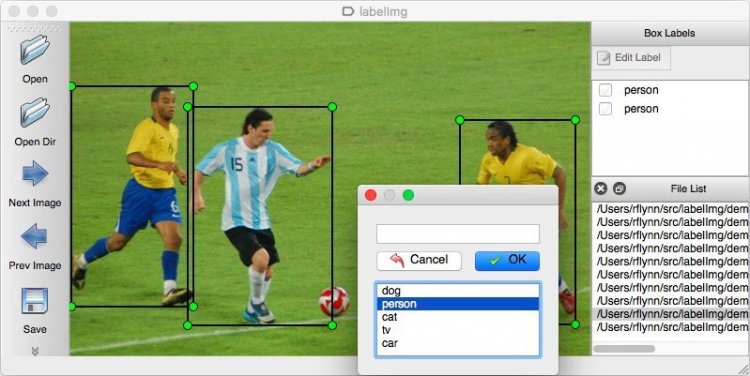
- LabelImg : графічний інструмент для розмітки об'єктів на картинках, додавання підписів і тегів зображень.
- Reveal.js : фреймворк для створення HTML-презентацій. Багато аналітиків використовують його на своїх виступах.
- PythonAnywhere: простий спосіб розгорнути онлайн легкий ML-проект на Python і супутніх бібліотеках.
- Sheety: перетворить Google Sheet в API і моделює дані в реальному часі.
- Jupyterthemes : втомилися від поточної теми Jupyter Notebook? Є багато інших.
- Light GBM: одна з популярних бібліотек для односторонньої вибірки на основі градієнта. В останні роки набула великої популярності, особливо на Kaggle.
- Machine Learning AZ: Practice Datasets and Codes: велике зібрання даних і коду на Python і R, що охоплює популярні алгоритми машинного навчання.
- Gradient by Paperspace: запускайте блокноти Jupyter безкоштовно на хмарнії машині, оснащенії графічними процесорами.
- Glueviz: візуалізують багатовимірні набори даних. Безкоштовний інструмент на основі Python (поставляється з Anaconda). Дуже добре підходить для пошуку зв'язків між наборами даних.
- Hot dog or not hot dog?: Мануал, який не потребує знань AI, машинного навчання і навіть програмування. Керівництво про те, як з IBM Watson написати програму для перевірки, чи є об'єкт хот-догом чи ні. Найважливіший ресурс в добірці ;-)
- FloydHub Workspaces: хмарне середовище розробки для глибокого навчання. Можна запускати блокноти Jupyter, скрипти Python, використовувати термінал і багато іншого.











0 комментариев
Добавить комментарий