Будь-який софт, призначений спеціально для нанесення шкоди системі, схожий на паразита - так чи інакше, він пошкоджує батьківську ОС. Щороку створюються тисячі зразків нових шкідливих програм, з яких антивірусами виявляються менше половини.

Ось деякі з традиційних методів, використовуваних для розпізнавання шкідливих програм:
- Виявлення в пісочниці. Підозріле ПО працює у віртуальному середовищі, де відслідковуються його дії. На основі спостережень антивірус з'ясовує, чи є програмне забезпечення шкідливим. Але цей метод можна обійти, якщо програма настільки величезна, що не може бути оброблена в віртуальному середовищі або коли небезпечний файл збережений в обфускаторному вигляді.
- Виявлення на основі сигнатур. Антивірусна компанія створює сигнатуру для шкідливих програм і оновлює їх в своїй БД. Антивірус порівнює сигнатуру відсканованого ПО з сигнатурами в базі. Проблема в тому, що неможливо створити підписи для кожного новоствореного зразка.
Тому в наші дні фахівці з кібербезпеки серед різних методів виявлення шкідливих компонентів стали застосовувати методи комп'ютерного зору і глибокого навчання. Детально ідея аналізу зображень для шкідливого ПО була описана в науковій публікації 2011 р Malware Images: Visualization and Automatic Classification. Ідея полягає в наступному: бінарний файл зчитується в вигляді 8-бітного вектора цілих чисел, а потім укладається в двовимірний масив. Такий масив зручно представити як зображення у відтінках сірого з діапазоном [0,255]( 0- чорний, 255- білий).
На малюнку нижче показаний приклад зображення для поширеного трояна Dontovo A, який завантажує і запускає довільні файли. Цікаво відзначити, що в багатьох випадках, як на малюнку, різні розділи (виконавчі фрагменти) шкідливого ПО демонструють різні текстури.

Відповідне зображення з публікації Malware Images: Visualization and Automatic Classification
Блок .text містить виконуваний код, в блоці .data знаходиться як неініціалізований код, так і ініціалізований дані, в розділі .rsrc зберігаються ресурси модуля, наприклад, іконки програми.
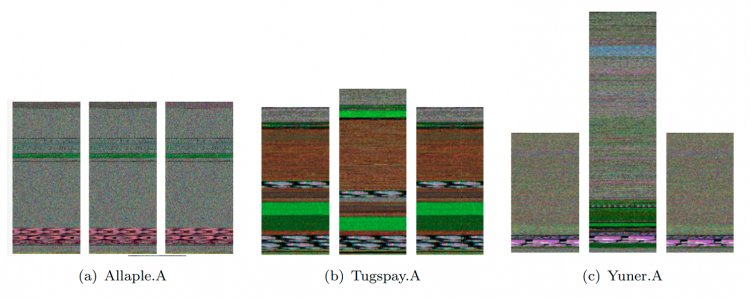
Віртуальні віруси так само, як реальні, мають схильність до мутації - виникають цілі сімейства вірусів. Порівняння показує, що програми всередині одного сімейства мають схожу структуру. Це дозволяє виявляти нові приклади шкідливих програм з уже відомої групи і навіть узагальнювати результати на ще невідомі сімейства.

Верхній ряд: відображення зразків шкідливих програм сімейства Fakerean, нижній ряд - відображення програм сімейства Donotvo.A
Надалі метод був модифікований і дозволив виявити і інші сімейства. Нижче представлено зображення, взято з дисертації 2017 р Malware Classification Using Image Representation .
Зразки шкідливого програмного забезпечення, оброблені з використанням колірної моделі
На зображенні наведено «знімки» шкідливих програм різних сімейств, отримані з використанням підходу, в якому використовується кольорове відображення.
Приклади обробки даних
Таким чином, для прискорення процесу виявлення шкідливого програмного забезпечення можна використовувати таке просте перетворення бінарного коду в зображення і звірення з відомими прикладами. Цей процес цілком можна довірити алгоритмам комп'ютерного зору. Як класичним підходам, так і розвинутим в останні роки нейромережевим рішенням.
Наприклад, у згаданій вище статті "Malware Images: Visualization and Automatic Classification" для обчислення текстурних ознак використовується вейвлет - декомпозиція зображення з використанням фільтра Габора, а також метод k-найближчих сусідів з евклідової відстані. Фільтр Габора - це лінійний фільтр, який аналізує частотний зміст зображення в певному напрямку в області аналізу. Він використовується для виявлення країв, аналізу текстур і вилучення об'єктів. Автори використовували базу даних з 9.5 тис. шкідливих програм з 25 сімейств, і отримали 98% точності виявлення.
У згаданій дисертації 2017 р Malware Classification Using Image Representation порівнювалися дві моделі: модель CNN з двома шарами згортки і двома щільними шарами (точність 95%) і модель Resnet18 (точність 98%).
У роботі 2016 р Convolution Neural Networks for Malware Classification автори навчали три моделі нейромереж з різною, досить складною архітектурою. Найкращі результати дала модель CNN 2C 1D, що складається з вхідного шару 32x32 пікселя, шарами з 64 і 128 фільтруючими картами розміром 3x3, двома max-pooling-шарами, щільно пов'язаних шаром з 512 нейронів і вихідного шару з 9 нейронів. Точність склала 99.8%.
Висновок
В наші дні зловмисники використовують автоматизований підхід до атак, і антивірусам важко захищати системи застарілими методами, коли код вірусу може змінюватись «на льоту». Методи комп'ютерного зору можуть надати істотну допомогу у виявленні шкідливих програм, виявляючи характерні образи і патерни.











0 комментариев
Добавить комментарий