Одне із завдань мовного моделювання - передбачити наступне слово, спираючись на знання попереднього тексту. Це потрібно для виправлення помилок, автодоповнення, чат-ботів і т.д. В інтернеті можна знайти багато інформації про моделі обробки природної мови. Ми зібрали четвірку популярних NLP-моделей в одному місці і порівняли їх, спираючись на документацію і наукові джерела.
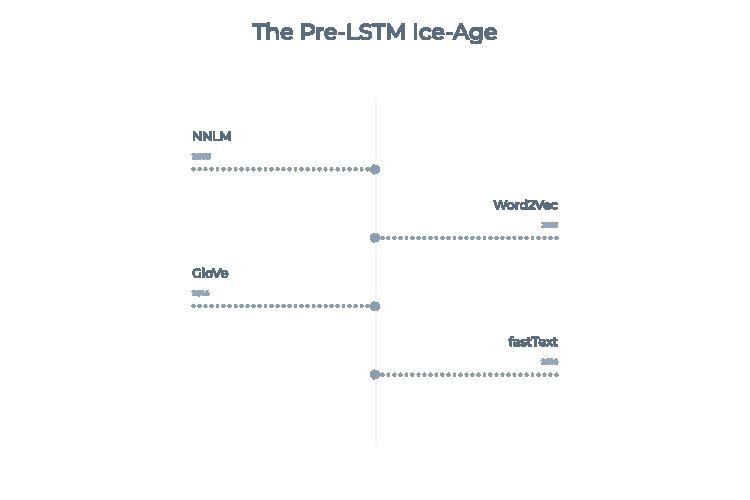
Тимчасова шкала, що виділяє чотири описувані моделі
1. Рекурентна нейромережева мовна модель (RNNLM)
Виникла в 2001 ідея привела до народження однієї з перших embedding-моделей.
Embeddings
У мовному моделюванні окремі слова і групи слів зіставляються векторам - деяким чисельним уявленням зі збереженням семантичної зв'язку. Стисле векторне подання слова називають ембеддінгом.
Модель приймає на вхід векторні уявлення nпопередніх слів і може «розуміти» семантику пропозиції. Навчання моделі базується на алгоритмі безперервного мішка слів. Контекстні (сусідні) слова подаються на вхід нейронної мережі, яка передбачає центральне слово.
Мішок слів
Мішок слів - це модель представлення тексту у вигляді вектора (набору слів). Кожному слову в тексті зіставляється число його входжень.
Стислі вектори об'єднуються, передаються в прихований шар, де спрацьовує softmax функція активації, яка визначає, які сигнали пройдуть далі.
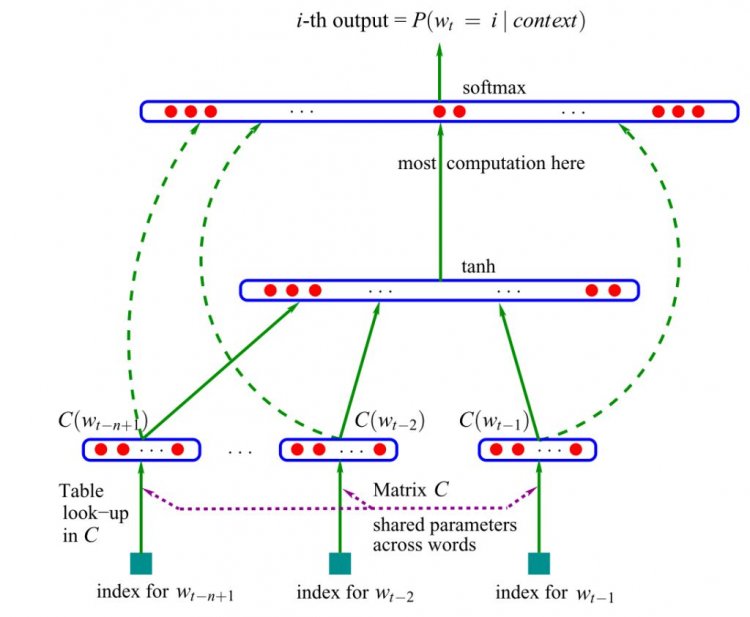
Схема нейронної мовної моделі прямого поширення
Оригінальна версія грунтувалася на нейромережах прямого поширення - сигнал йшов строго від вхідного шару до вихідного. Пізніше була запропонована альтернатива у вигляді рекурентних нейронних мереж (RNN) - саме на «ванільній» RNN, а не на керованих зворотних блоках (GRUs) або на довгій короткостроковій пам'яті (LSTM).
Рекурентні нейронні мережі (RNN)
Нейронні мережі з спрямованими зв'язками між елементами. Вихід нейрона може знову подаватися на вхід. Така структура дозволяє мати подобу «пам'яті» і обробляти послідовності даних, наприклад, тексти природної мови.
Готові моделі
У Google є попередньо навчені open-source моделі для більшості мов (англійська версія). Модель використовує три приховані прошарки нейронної мережі прямого поширення, навчена на корпусі English Google News 200B і генерує 128-мірний ембеддінг.
Переваги
- Простота. Модель швидко навчається і генерує ембеддінги, яких достатньо для більшості простих додатків.
- Попередньо навчені версії доступні на багатьох мовах.
Недоліки
- Не враховує довгострокові залежності.
- Простота обмежує можливості використання.
- Нові embeddings моделі набагато могутніше.
2. Word2vec
У 2013 році Томас Міколов (Tomas Mikolov) з Google запропонував більш ефективну модель навчання векторних уявлень слів - Word2vec. Метод ґрунтувався на припущенні, що слова, які часто знаходяться в однакових контекстах, мають схожі значення. Зміни були прості - усунення прихованого шару і апроксимація (спрощення) мети - але стали поворотною точкою в розвитку мовних моделей NLP.
Замість алгоритму безперервного мішка слів модель Word2Vec використовує Skip-gram (словосполучення з пропуском). Мета цієї моделі прямо протилежна попередній моделі - передбачити навколишні слова на основі центрального.
Skip-Gram
Формується «контекстне вікно» - послідовність з k слів в тексті. Одне з цих слів пропускається, і нейромережа намагається його передбачити. Таким чином, слова, які часто зустрічаються в схожому контексті, матимуть схожі вектори.
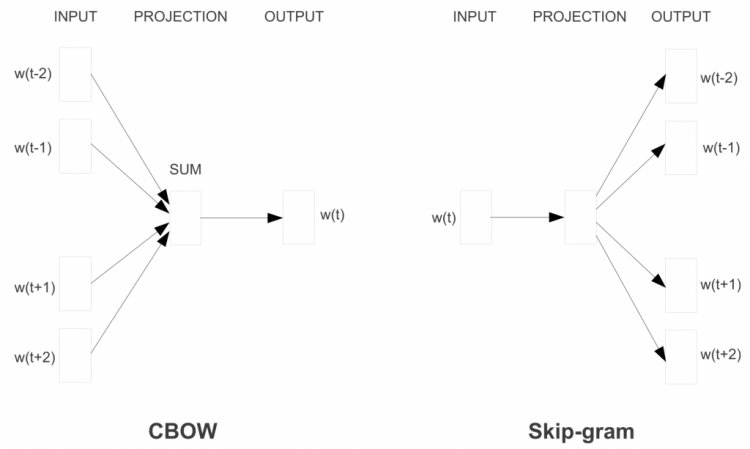
Архітектури Continuous bag of words і Skip-gram
Щоб зробити навчання ефективніше, використовується негативне семпліювання (Negative Sampling): моделі надаються слова, які не є контекстними сусідами.
Negative Sampling
Багато слів в текстах невідомі разом, тому модель виконує багато зайвих обчислень. Підрахунок softmax - обчислювально дорога операція. Підхід Negative Sampling дозволяє максимізувати ймовірність зустрічі потрібного слова в контексті, який є для нього типовим, і мінімізувати - в рідкісному / нетиповому контексті.
Векторна магія
Модель Word2vec вразила дослідників своєю «інтерпритованістю». Навчання на великих корпусах текстів дозволяє визначати глибокі відносини між формами слів, наприклад, гендерні. Якщо з вектора, відповідного слову Чоловік (Man) відняти вектор Жінка (Woman), результат буде дуже схожий на різницю векторів Король (King) і Королева (Queen).
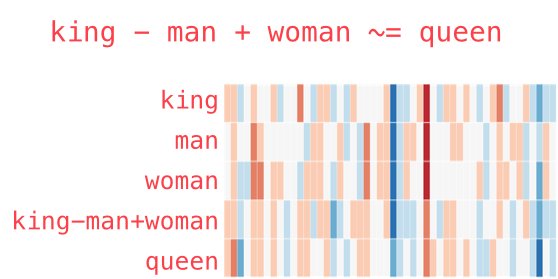
У свій час таке відношення між словами і їх векторами здавалося майже магією. Незважаючи на величезний внесок, який модель внесла в NLP, зараз вона майже не використовується - на зміну прийшли гідні спадкоємці.
Готові моделі
Попередньо навчена модель легко доступна в інтернеті. В Python-проект її можна імпортувати за допомогою бібліотеки gensim.
Переваги
- Проста архітектура: feed-forward, 1 вхід, 1 прихований шар, 1 вихід.
- Модель швидко навчається і генерує ембеддінги (навіть ваші власні).
- Ембеддінги наділені змістом, спірні моменти піддаються розшифровці.
- Методологія може бути поширена на безліч інших областей / проблем (наприклад, Lda2vec ).
Недоліки
- Навчання на рівні слів: немає інформації про пропозицію або контекст, в якому використовується слово.
- Спільна зустрічальність ігнорується. Модель не враховує те, що слово може мати різне значення в залежності від контексту використання. Це основна причина, по якій GloVe зазвичай краще Word2Vec.
- Не дуже добре обробляє невідомі і рідкісні слова.
3. GloVe (Global Vectors)
GloVe тісно асоціюється з Word2Vec: алгоритми з'явилися приблизно в один і той же час і спираються на інтерпритацію векторів слів. Модель GloVe намагається вирішити проблему ефективної використання статистики збігів. GloVe мінімізує різницю між добутком векторів слів і логарифмом ймовірності їх спільної появи за допомогою стохастичного градієнтного спуску. Отримані уявлення відображають важливі лінійні підструктури векторного простору слів: виходить зв'язати разом різні супутники однієї планети або поштовий код міста з його назвою.
Зв'язок назви міста і його поштового коду
У Word2Vec частота спільної зустрічності слів не має великого значення, вона лише допомагає генерувати додаткові навчальні вибірки. GloVe враховує спільну зустрічність, а не покладається лише на контекстну статистику. Вектори слів групуються разом на основі їх глобальної схожості.
Готові моделі
Ембеддінги GloVe легко доступні на веб-сайті Стенфордського університету .
Переваги
- Проста архітектура без нейронної мережі.
- Модель швидка, і цього може бути достатньо для простих додатків.
- Осмислені ембеддінги.
Недоліки
- Хоча матриця спільної зустрічності надає глобальну інформацію, GloVe залишається навченою на рівні слів і дає трохи даних про пропозицію і контекст, в якому слово використовується.
- Погано обробляє невідомі і рідкісні слова.
4. fastText
Створена в Facebook бібліотека fastText - ще один серйозний крок у розвитку моделей природної мови. В її розробці взяв участь Томас Міколов, вже знайомий нам по Word2Vec. Для векторизації слів використовуються одночасно і skip-gram, і негативне семпліюваання, і алгоритм безперервного мішка.
До основної моделі Word2Vec додана модель символьних n-грам. Кожне слово представляється композицією декількох послідовностей символів певної довжини. Наприклад, слово they в залежності від гіперпараметрів може складатися з "th", "he", "ey", "the", "hey". По суті, вектор слова - це сума всіх його n-грам.
Результати роботи класифікатора добре підходять для слів з невеликою частотою вживання, так як вони поділяються на n-грами. На відміну від Word2Vec і Glove, модель здатна генерувати ембеддінги для невідомих слів.
Готові моделі
У мережі доступна підготовлена модель для 157 мов.
Переваги
- Проста архітектура: feed-forward, 1 вхід, 1 прихований шар, один вихід (хоча n-грами додають складність в генерацію ембеддінгів).
- Завдяки n-грамам непогано працює на рідкісних і застарілих словах.
Недоліки
- Навчання на рівні слів: немає інформації про пропозицію або контекст, в якому використовується слово.
- Ігнорується спільна зустрічність, тобто модель не враховує різне значення слова в різних контекстах (тому GloVe може бути краще).
***
Всі чотири моделі мають багато спільного, але кожна з них повинна використовуватися в потрібному контексті. На жаль, цей момент часто ігнорується, що призводить до отримання неоптимальних результатів.











0 комментариев
Добавить комментарий