Загальні принципи створення софта на Java, здатного обробляти тисячі коннектів: кешування TCP-з'єднань, робота з потоками і буферами, пропускна здатність і спеціальні утиліти.
Проблема C10k - це термін, що позначає десять тисяч одночасно оброблюваних з'єднань. Для вирішення проблеми часто доводиться вносити зміни в налаштування мережевих сокетів і Linux, стежити за використанням буферів відправки і прийому TCP і черг.

1. Зробіть додаток під C10k
Коли потрібно максимально продуктивно використовувати процесор, слід тримати кількість потоків близьким до числа процесорів, виділених для програми. Спираючись на це, слід підібрати неблокуючу логіку з високим співвідношенням часу обробки CPU / IO.
Іноді буде потрібно перебудувати код, додавши RabbitMQ або Kafka, для зміни розподіленої системи, щоб мати можливість буферизувати таски і відокремити неблокуючий код від того коду, який не вийде легко переписати.
Неблокуючий код дозволить:
- Розділити додаток на дві частини. Наприклад, одна частина - це REST, яка може бути реалізована за допомогою HTTP-сервера на основі пулу потоків, а друга частина - клієнт, який записує щось у БД.
- Масштабувати кількість примірників цих двох частин по-різному, тому як дуже ймовірно, що навантаження / процесор / пам'ять абсолютно різні.
На що ще звернути увагу:
- Зберігайте якомога менше потоків. Перевіряйте не тільки серверні потоки, а й інші частини програми: клієнт, драйвер БД, налаштування журналу. Завжди робіть дамп потоку, щоб бачити кількість потоків і їх зміст. Виконуйте це під навантаженням, інакше пули потоків не будуть повністю ініціалізовані. Називайте призначені для користувача потоки зрозумілим чином - так буде простіше супроводжувати код.
- Пам'ятайте про блокування викликів HTTP / DB. Можна використовувати реактивні клієнти, які автоматично реєструють для вхідної відповіді зворотний виклик. Розгляньте можливість використання протоколу для зв'язку service-2-service, наприклад, RSocket .
- Перевірте, чи містить додаток постійно низьку кількість потоків, чи має він пули потоків і чи здатен витримати необхідне навантаження.
Якщо додаток має кілька потоків обробки, завжди перевіряйте, які з них блокуються. При великій кількості блокуючих потоків вам буде потрібно майже кожен запит обробити в іншому потоці, щоб звільнити потік циклу подій для наступного з'єднання.
В цьому випадку розгляньте можливість використання HTTP-сервера на основі thread-pool з Воркер, де всі запити поміщаються в інший потік з величезного пулу для збільшення пропускної здатності - іншого способу немає, якщо ми не в змозі позбутися від блокуючих викликів.
2. Кешуйте з'єднання, а не потоки
Цей принцип тісно пов'язаний з темою програмування моделей для HTTP-сервера. Основна ідея полягає не в прив'язці з'єднання до одного потоку, а в використанні деяких бібліотек, що підтримують ефективний підхід читання з TCP.
Найважливіша частина - це рукостискання TCP. Ви завжди повинні підтримувати keep-alive з'єднання. Якби ми використовували TCP-з'єднання тільки для відправки одного повідомлення, ми б оплатили накладні витрати в розмірі 8 сегментів TCP ( connect and close the connection= 7 сегментів).
Підтвердження нового TCP-з'єднання
Якщо ми знаходимося в ситуації, коли немає можливості використовувати постійне з'єднання, то дуже ймовірно, що за короткий проміжок часу накопичиться велика кількість створених з'єднань. Вони повинні бути поставлені в чергу і чекати сигналу від додатка.
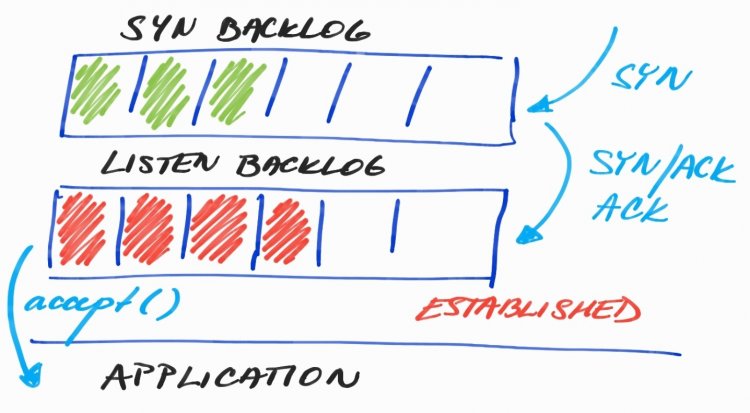
Структура взаємодії беклогів TCP-з'єднання
На малюнку беклогі SYN і LISTEN. В SYN знаходяться сполуки, які очікують використання в TCP-рукостисканні. А в LISTEN- повністю початкові з'єднання, з буферами відправки і прийому. Якщо хочете дізнатися, чому потрібні два беклога, почитайте даний матеріал.
Є ще одна проблема. Під навантаженням при великому числі вхідних з'єднань потоки додатків, що відповідають за прийом з'єднань, можуть бути зайняті іншою роботою - виконанням IO для вже підключених клієнтів.
var bossEventLoopGroup = new EpollEventLoopGroup(1);
var workerEventLoopGroup = new EpollEventLoopGroup();
new ServerBootstrap()
.channel(EpollServerSocketChannel.class)
.group(bossEventLoopGroup, workerEventLoopGroup)
.localAddress(8080)
.childOption(ChannelOption.SO_SNDBUF, 1024 * 1024)
.childOption(ChannelOption.SO_RCVBUF, 32 * 1024)
.childHandler(new CustomChannelInitializer());
У наведеному фрагменті (конфіг Netty Server API) знаходяться bossEventLoopGroup і workerEventLoopGroup. У той час як workerEventLoopGroup за замовчуванням створюється з ( CPU * 2) потоками / циклами для виконання IO-операцій, bossEventLoopGroup містить один потік для прийому нових з'єднань. Netty дозволяє мати тільки одну групу для обох дій, але в цьому випадку прийняття нових з'єднань може довго чекати через виконання IO або більш тривалих операцій.
Легко перевірити, чи здатний процес витримати навантаження вхідних з'єднань - трохи модифікувавши Websocket-Broadcaster для підключення 20 000 клієнтів:
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 42 128 *:8081 *:* users:(("java",pid=7418,fd=86))
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:8081 *:* users:(("java",pid=7418,fd=86))
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 20 128 *:8081 *:* users:(("java",pid=7418,fd=86))
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 63 128 *:8081 *:* users:(("java",pid=7418,fd=86))
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:8081 *:* users:(("java",pid=7418,fd=86))
- Send-Q: Загальний розмір беклога LISTEN.
- Recv-Q: Поточна кількість підключень в беклозі LISTEN.
Поточний дефолтний розмір беклога LISTEN
cat /proc/sys/net/core/somaxconn
128
Буфери Send / Receive
Коли з'єднання готове, найбільш проблемними частинами є буфері send / receive, які використовуються для передачі байтів з програми, в базовий мережевий стек. Розмір цих буферів можна налаштовувати:
new ServerBootstrap()
.channel(EpollServerSocketChannel.class)
.group(bossEventLoopGroup, workerEventLoopGroup)
.localAddress(8080)
.childOption(ChannelOption.SO_SNDBUF, 1024 * 1024)
.childOption(ChannelOption.SO_RCVBUF, 32 * 1024)
.childHandler(new CustomChannelInitializer());
Додаткові відомості про параметри сокетів в Java прочитайте в офіційному хелпі StandardSocketOptions. Нові версії Linux здатні автоматично налаштовувати буфери для досягнення оптимального розміру в поточному навантаженні за допомогою TCP Congestion Window.
Великі буфери можуть привести до витоку пам'яті, а маленькі - задушать додаток, бо не буде місця для передачі байтів в / з мережевого стека.
Чому кешування потоку це погано?
Java Thread - «дорогий» об'єкт, адже він зіставлений один в один з потоком ядра. В Java ми можемо обмежити розмір стека потоку за допомогою опції -Xss, яка за умовчанням встановлена в 1 Мб. Це означає, що один потік займає 1 Мю віртуальної пам'яті, а не Committed Memory. Якщо не використовуються жадібні фреймворки або рекурсія, розмір потоку становить 200-300 кБ. Цей вид пам'яті належить до Native Memory, а всі моменти можна відстежити за допомогою Native Memory Tracking.
$ java -XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary /
-XX:+PrintNMTStatistics -version
openjdk version "11.0.2" 2019-01-15
OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.2+9)
OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.2+9, mixed mode)
Native Memory Tracking:
Total: reserved=6643041KB, committed=397465KB
- Java Heap (reserved=5079040KB, committed=317440KB
(mmap: reserved=5079040KB, committed=317440KB)
- Class (reserved=1056864KB, committed=4576KB)
(classes #426)
( instance classes #364, array classes #62)
(malloc=96KB #455)
(mmap: reserved=1056768KB, committed=4480KB)
( Metadata: )
( reserved=8192KB, committed=4096KB)
( used=2849KB)
( free=1247KB)
( waste=0KB =0,00%)
( Class space:)
( reserved=1048576KB, committed=384KB)
( used=270KB)
( free=114KB)
( waste=0KB =0,00%)
- Thread (reserved=15461KB, committed=613KB)
(thread #15)
(stack: reserved=15392KB, committed=544KB)
(malloc=52KB #84)
(arena=18KB #28)
Інша проблема з великою кількістю потоків - величезний Root Set. Наприклад, є 4 процесора і 200 потоків. В цьому випадку ви можете запустити тільки 4 потоки, але якщо всі 200 потоків вже зайняті обробкою, ви заплатите більшу ціну за об'єкти, розташовані в купі, так як даний потік чекає вільний процесорний час.
Чому Root Set - це така велика проблема?
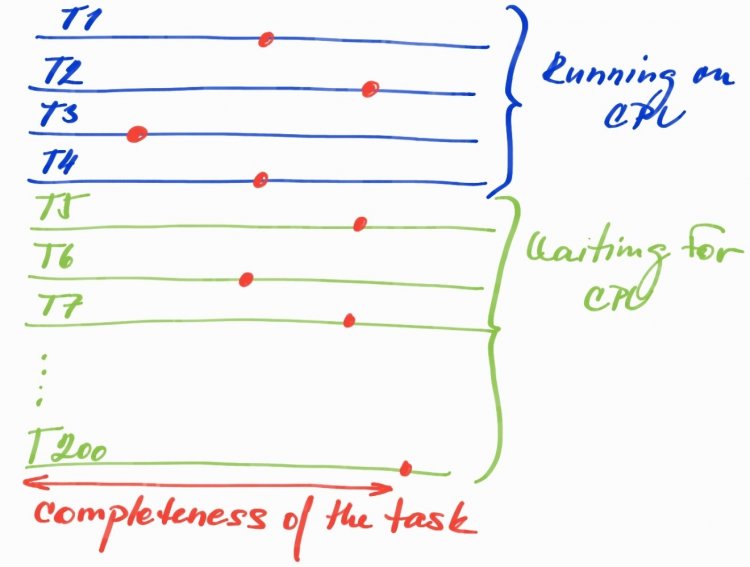
Червоні точки можуть позначати будь-який момент часу, коли працюють тільки 4 потоки, а інші просто чекають в черзі. Область Completeness of the task не означає, що всі об'єкти, виділені до сих пір, все ще живі, вони вже могли бути зібрані в сміття або очікують наступного циклу збирача сміття. Що тут не так?
- Занадто великий Live Set: кожен потік зберігає виділені живі об'єкти в купі, який просто чекає. Цей момент потрібно тримати в пам'яті, коли ми визначаємо розмір.
- Великі паузи GC через більшу Root Set , ускладнюють роботу збирача сміття. Сучасні збирачі починають з ідентифікації Root Set ( Snapshot-At-The-Beginning - робота з живими потоками), а потім проходять через граф, щоб знайти поточний Live Set. Чим більше Root Set, тим більше роботи для GC.
- Рух до Old Generation: великий Live Set також буде впливати на час, протягом якого даний об'єкт буде вважатися живим. Це збільшує ймовірність того, що об'єкт буде переведений в Old Generation, навіть якщо потік, який зберігає цей об'єкт, провів більшу частину свого часу поза ЦП.
3. Припиняємо генерувати сміття
Для написання програми, яка буде знаходитися під великим навантаженням, необхідно подумати про виділення всіх об'єктів і не дозволяти JVM витрачати ні одного байта. У цьому допоможе ByteBuffers.
Клас ByteBuffer має дві опції: HeapByteBuffer і DirectByteBuffer. Ключова користь DirectByteBuffers - можливість передавати безпосередньо в нативні функції ОС виконання I / O. Іншими словами, коли ви працюєте з I / O в Java, ви передаєте посилання на DirectByteBuffer (зі зміщенням і довжиною).
Розглянемо на прикладі. У вас є 10k з'єднань, і ви хочете їм передати одне і те ж значення рядка. Немає ніякої причини передавати рядок 10k раз або ще гірше, генерувати новий об'єкт String для кожного з'єднання, засмічуючи купу одним і тим же масивом байтів. Замість цього ми можемо створити власний DirectByteBuffer і надати його всім з'єднанням, а потім дозволити їм передати все в ОС через JVM.
Є одне але - DirectByteBuffer дуже «дорого» виділяти. Тому в JDK кожен потік, який працює з I / O, кешує один DirectByteBuffer для внутрішнього використання.
Але навіщо тоді потрібен HeapByteBuffer, якщо його потрібно перетворити в DirectByteBuffer для можливості запису в ОС? HeapByteBuffer набагато дешевше обходиться. Якщо ми повернемося в приклад вище, то ми могли б виключити перший крок і не робити це 10k-раз. Тоді можна розраховувати на автоматичний механізм кешування DirectByteBuffer для кожного потоку всередині JDK.
4. Вимірюємо навантаження в години пік
Ознайомтеся з корисним набором утиліт для роботи з TCP: BCC Tools і bpftrace.
Використовуючи bpftrace, можна отримати швидкий результат для дослідження можливої проблеми. Приклад демонструє, як socketio-pid.bt підраховує кількість переданих байтів на основі PID:
#!/snap/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("Socket READS/WRITES and transmitted bytes, PID: %u\n", $1);
}
kprobe:sock_read_iter,
kprobe:sock_write_iter
/$1 == 0 || ($1 != 0 && pid == $1)/
{
@kiocb[tid] = arg0;
}
kretprobe:sock_read_iter
/@kiocb[tid] && ($1 == 0 || ($1 != 0 && pid == $1))/
{
$file = ((struct kiocb *)@kiocb[tid])->ki_filp;
$name = $file->f_path.dentry->d_name.name;
@io[comm, pid, "read", str($name)] = count();
@bytes[comm, pid, "read", str($name)] = sum(retval > 0 ? retval : 0);
delete(@kiocb[tid]);
}
kretprobe:sock_write_iter
/@kiocb[tid] && ($1 == 0 || ($1 != 0 && pid == $1))/
{
$file = ((struct kiocb *)@kiocb[tid])->ki_filp;
$name = $file->f_path.dentry->d_name.name;
@io[comm, pid, "write", str($name)] = count();
@bytes[comm, pid, "write", str($name)] = sum(retval > 0 ? retval : 0);
delete(@kiocb[tid]);
}
END
{
clear(@kiocb);
}
Бачимо п'ять потоків ( server-io-x ) і кожен потік висить в циклі подій. Кожен цикл має одного підключеного клієнта, і додаток транслює випадково сгенероване строкове повідомлення всім підключеним клієнтам за допомогою протоколу Websocket.
- @bytes - сума r / w байтів;
- @io - загальна кількість операцій r / w.
./socketio-pid.bt 27069
Attaching 6 probes...
Socket READS/WRITES and transmitted bytes, PID: 27069
^C
@bytes[server-io-3, 27069, read, TCPv6]: 292
@bytes[server-io-4, 27069, read, TCPv6]: 292
@bytes[server-io-0, 27069, read, TCPv6]: 292
@bytes[server-io-2, 27069, read, TCPv6]: 292
@bytes[server-io-1, 27069, read, TCPv6]: 292
@bytes[server-io-3, 27069, write, TCPv6]: 1252746
@bytes[server-io-1, 27069, write, TCPv6]: 1252746
@bytes[server-io-0, 27069, write, TCPv6]: 1252746
@bytes[server-io-4, 27069, write, TCPv6]: 1252746
@bytes[server-io-2, 27069, write, TCPv6]: 1252746
@io[server-io-3, 27069, read, TCPv6]: 1
@io[server-io-4, 27069, read, TCPv6]: 1
@io[server-io-0, 27069, read, TCPv6]: 1
@io[server-io-2, 27069, read, TCPv6]: 1
@io[server-io-1, 27069, read, TCPv6]: 1
@io[server-io-3, 27069, write, TCPv6]: 1371
@io[server-io-1, 27069, write, TCPv6]: 1371
@io[server-io-0, 27069, write, TCPv6]: 1371
@io[server-io-4, 27069, write, TCPv6]: 1371
@io[server-io-2, 27069, write, TCPv6]: 1371
5. Баланс між пропускною спроможністю і затримкою
Продуктивність додатку рано чи пізно впирається в компроміс між пропускною спроможністю і затримкою. Припустимо, що у нас є Netty і WebSocket-сервер, який відправляє повідомлення підключеним клієнтам. Чи дійсно нам потрібно відправити повідомлення якомога швидше? Або можна почекати, створити пакет з п'яти повідомлень і відправити їх разом?
Netty підтримує механізм, що ідеально підходить для цього випадку. Припустимо, ми вирішили пожертвувати затримкою на користь загальної пропускної здатності при створенні пакета.
pbouda.jfr.sockets.netty.server.SlowConsumerDisconnectHandler:
- we need to comment out flushing of every message and use simple write instead
- write method does not automatically write data into the socket, it waits for a flush context.writeAndFlush(obj) -> context.write(obj
pbouda.jfr.sockets.netty.Start#main
- uncomment the section at the end of the method `Flush a bulk of 5 messages`
Якщо у вас стоїть Java 14, що включає в себе функцію Java Flight Recorder Streaming , то ви можете побачити, як діє Netty в даному випадку:
Broadcaster-Server 2020-01-14 22:12:00,937 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
Broadcaster-Server 2020-01-14 22:12:00,937 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
Broadcaster-Server 2020-01-14 22:12:00,938 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
Broadcaster-Server 2020-01-14 22:12:00,938 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
Broadcaster-Server 2020-01-14 22:12:00,939 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
jdk.SocketWrite {
startTime = 22:12:01.603
duration = 2.23 ms
host = ""
address = "127.0.0.1"
port = 42556
bytesWritten = 60 bytes
eventThread = "server-nioEventLoopGroup-1" (javaThreadId = 27)
stackTrace = [
sun.nio.ch.SocketChannelImpl.write(ByteBuffer[], int, int) line: 167
io.netty.channel.socket.nio.NioSocketChannel.doWrite(ChannelOutboundBuffer) line: 420
io.netty.channel.AbstractChannel$AbstractUnsafe.flush0() line: 931
io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.flush0() line: 354
io.netty.channel.AbstractChannel$AbstractUnsafe.flush() line: 898
...
]
}
jdk.SocketRead {
startTime = 22:12:01.605
duration = 0.0757 ms
host = ""
address = "127.0.0.1"
port = 8080
timeout = 0 s
bytesRead = 60 bytes
endOfStream = false
eventThread = "client-nioEventLoopGroup-0" (javaThreadId = 26)
stackTrace = [
sun.nio.ch.SocketChannelImpl.read(ByteBuffer) line: 73
io.netty.buffer.PooledByteBuf.setBytes(int, ScatteringByteChannel, int) line: 247
io.netty.buffer.AbstractByteBuf.writeBytes(ScatteringByteChannel, int) line: 1147
io.netty.channel.socket.nio.NioSocketChannel.doReadBytes(ByteBuf) line: 347
io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read() line: 148
...
]
}
Підключений клієнт отримав п'ять повідомлень, але ми бачимо тільки один сокет для читання і запису, і обидва містять весь пакет повідомлень.
6. Не відставайте від нових тенденцій
Тут представлені дві концепції, які в даний час стають сильними варіантами обробки великої кількості клієнтів / запитів, навіть якщо вони явно не пов'язані з вирішенням проблеми C10k.
GraalVM Native Image - для економії ресурсів
GraalVM - потужна штука, яка працює на AOT-компіляторі і включає в себе фреймворк SubstrateVM. У двох словах це означає, що Graal використовується під час складання для генерації машинного коду без будь-яких даних профілювання.
Він буде генерувати автономний двійковий файл без будь-яких зайвих класів / методів, внутрішніх структур, таких як JIT-структури даних. Така оптимізація гарантує, що ми зможемо запускати наш додаток з набагато меншим об'ємом пам'яті, і навіть якщо програма має менш ефективний код, ми можемо в кінцевому підсумку отримати краще співвідношення між споживаною пам'яттю і загальною кількістю оброблених запитів. Це означає, що ми можемо розгорнути кілька примірників додатку з ще більшою пропускною спроможністю і меншою кількістю ресурсів.
Проект Loom - усунення проблем від блокування викликів
Ви, напевно, чули про fibers/green threads/goroutines. Всі ці терміни означають одне - уникнути планування потоків в ядрі, делегуючи відповідальність в простір користувача. Типовим прикладом є те, що у нас є багато блокуючих викликів, кожен запит до додатуа закінчується в JDBC/HTTP/. Далі відбувається виклик. Нам потрібно заблокувати поточний потік Java і чекати, поки не повернеться відповідь.
Замість цього ми можемо використовувати Fibers з Project Loom. Це гарантує, що блокуючий виклик фактично не блокує потік Java, а тільки поточний Fiber. Тому ми можемо запланувати новий Fiber на поточній запущеної Java, а потім повернутися до вихідного Fiber, коли блокуючий виклик буде виконаний. Результатом буде можливість обробляти всі запити, навіть з дуже обмеженим числом потоків Java, тому що Fibers «майже безкоштовний».
Висновок
Спроба перемогти проблему C10k в основному пов'язана з ефективністю використання ресурсів. Код, який абсолютно нормально працює з десятками / сотнями паралельних користувачів, може підвести, коли ми підсунемо йому тисячі паралельних з'єднань.
Це абсолютно нормально, якщо додаток не призначений для такої великої кількості з'єднань, бо далеко не весь софт може вивезти подібне. Але завжди корисно знати про ці принципи і почати розробляти високопродуктивний додаток з нуля, уникнувши складності розширених функцій для збереження кожного байта пам'яті в умовах обробки великої кількості клієнтів.











0 комментариев
Добавить комментарий