Боретеся з навантаженням бази даних PostgreSQL? На прикладах розглянемо, звідки вони з'являються і як позбутися від них шляхом оптимізації запитів.
Незважаючи на горизонтальну масштабованість архітектури з чергами, воркерами і stateless-інтерфейсами, часом база даних стає слабким місцем, оскільки деякі програмісти пишуть такі запити, що страшно глянути.
Подивіться на наступний план запиту, в якому знайдете і CTE, і APPEND, і GROUP BY, і ORDER BY. Уявіть, як це оптимізувати.

Обговоримо звичайні запити в спрощеному варіанті.
Перегляньте схему даних
У першому прикладі розробник зберігає JSON в словнику - в PostgreSQL це тип hstore. Далі розгортає значення в рядок всередині підзапиту, а в зовнішньому запиті робить пошук поля token і порівнює його з конкретним параметром.

Такі операції призводять до послідовного сканування (SeqScan) всієї таблиці. Яке виправдання можна знайти: через JSON всередині hstore індекс не зробиш, тобто не оптимізуєш.
Рішення виявилося простим. Аналіз показав, що JSON з таким токеном у нас менше 1%, тому колонку прибрали і винесли таблицю в окрему сутність.
Обережніше з CTE
Часто розробники помиляються щодо CTE-команди WITH: це не представлення (VIEW), яке підставляється в наступний запит. Спочатку виконується WITH, а тільки потім його результат передається в інший запит. Тому такий запит сканує всі документи на диску, щоб у зовнішньому запиті розробник отримав єдиний необхідний файл:

Як зменшити вибірку WITH з купи рядків до одного? Перенесіть туди перевірку умови. По цьому полю був маленький індекс B-Tree.

Результат такої оптимізації:
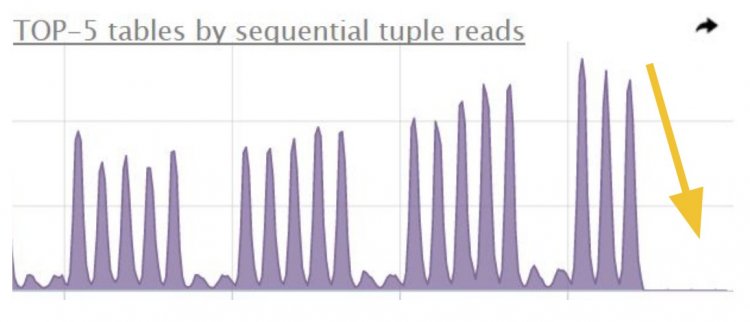
Позбавляйтеся від зайвих даних
Розглянемо зберігання непотрібних даних на прикладі списку системних новин. Уявіть, розробник вносить в окрему колонку типу hstore список ідентифікаторів користувачів, які підписалися на показ цієї новини - людей сотні тисяч. Прийшов час, коли один користувач влаштував глобальну відписку, і без перевірки виконується ось такий запит:
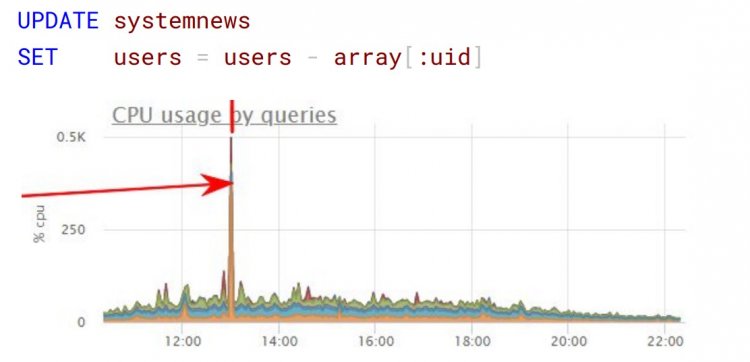
Так як в PostgreSQL при оновленні запису оригінал позначається на видалення і створюється новий рядок, подібний запит за фактом скопіював майже всю таблицю з гігабайтами даних, навантаживши диск і процесор.
Що не так з цим запитом? На перший погляд, ідеальне оновлення по первинному ключу:

Насправді, запит розраховував метрики на підставі дій користувача в особистому кабінеті. Але частіше результат розрахунку дорівнював значенню, збереженому в базі даних, а оновлення ставали марними. Додавання перевірки content != :new content на порядок скоротило кількість UPDATE:
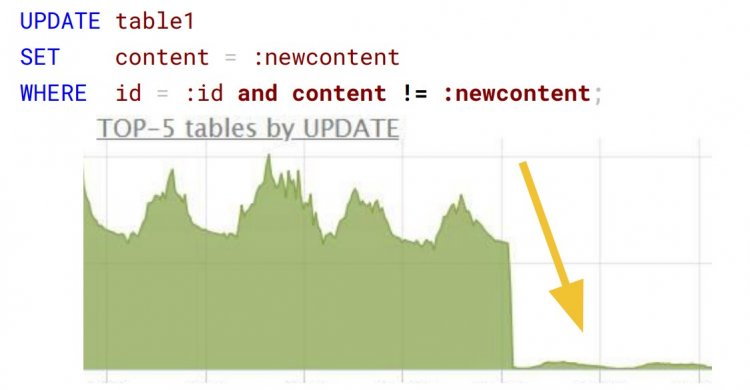
Перевірте код на бекенді
Наступний приклад невинного запиту: установка нового значення і ключа в hstore. Проблема в тому, що розробник запускав цей запит при ітерації, додаючи туди купу нових ідентифікаторів. У масштабі 100 тисяч користувачів словник збільшувався і давав непомірне для конкретного сервісу навантаження:
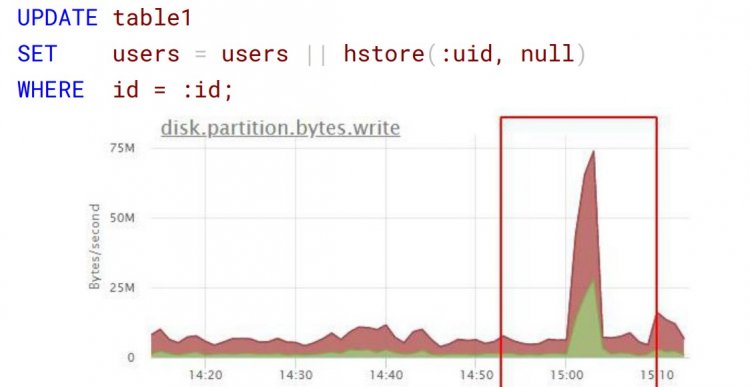
Варіант оптимізації - сформувати на бекенді один запит і відправити відразу всі зміни в базу.
Слідкуйте за розмірами IN
Іноді розробник, здавалося б, виправдано робить гігантський запит, замість того щоб тисячу разів звертатися до бази даних в циклі за додатковою інформацією:

Але тут підвела купа індексів в одній таблиці. Між індексом на companyid і простим B-Tree на companyid + groupname PostgreSQL вибрав перше: прочитав мільйони операцій по companyid і відфільтрував результат по groupname. Хоча groupname містив всього тисячу елементів.
Для вирішення проблеми спершу зменшили індекс, оскільки groupname зустрічався не у всіх компаній:

При детальному аналізі коду виявилося, що додаткова інформація потрібна в рідкісних випадках, тому запит навпаки перенесли в розгалуження циклу. Незважаючи на збільшення кількості запитів, швидкість зросла, тому що з великого IN отримали одноелементний.
Виправляйте структуру запиту
Пам'ятайте приклад з системними новинами? Розглянемо схожий, тільки з прив'язкою до двох сутностей: користувачів і компаній.

Щоб користувач при вході в особистий кабінет бачив свої повідомлення, а потрапляючи в компанію - відповідне оточення, написали такий запит:

На hstore навішують GIN-індекс, який повертає бітову карту, або при великій кількості даних - слабку карту з ідентифікаторами сторінок. Але виконання сортування для компанії з сотнею тисяч записів переповнило робочу пам'ять і призвело до такого божевілля на диску:
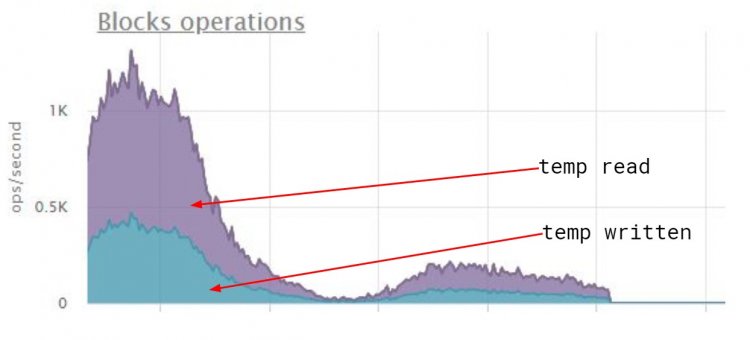
Оскільки GIN-індекс зберігає дані без певного порядку, довелося виправити структуру запиту: коли зробили первинним ключем userid+ companyid+ id, швидкість виконання виросла на очах.

Призначайте тайм-аути
Для деяких запитів повільна швидкість - нормальне явище. Уявіть: ваш сервіс робить розрахунки і збирає звіт по конкретним категоріям, а користувач сам вибирає період для вибірки.
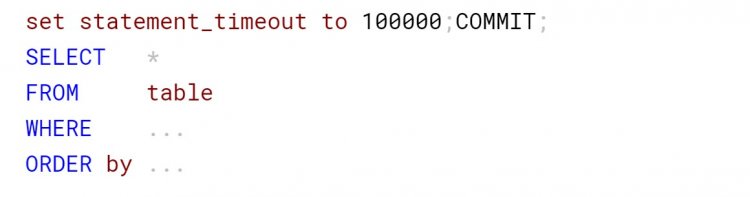
Стояло обмеження часу виконання в 100 секунд на SQL Provider: через заданий час прилітала помилка сервера баз даних, на що користувач повторював запит. Але при цьому провайдер не закінчує перший запит, і на сервері виконувалося вже два однакових важких запити, які боролися за системні ресурси.
Як вдалося змусити провайдер завершувати запит після закінчення тайм-ауту? Встановили змінну сесії statement_timeout в 100 секунд.
Перевіряйте на існування правильно
Коли розробникам кажуть перевірити існування хоч одного запису в базі даних, деякі обчислюють загальну кількість рядків з перевіркою купи умов і пишуть return count > 0:

Замість цього використовуйте EXISTS з константою, оскільки оператор завершує запит, як тільки зустріне підходящий запис:

Використовуйте BRIN-індекс
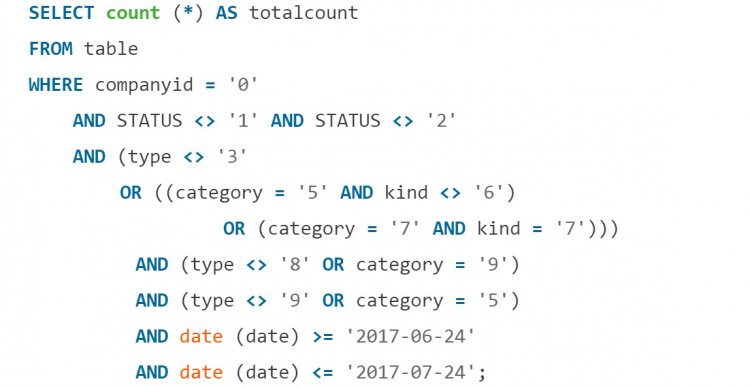
Іноді від замовника прилітає завдання порахувати загальну кількість чогось. Ви хоч раз цікавилися, скільки отримали всього повідомлень на пошті або в месенджері? А комусь подібне знадобилося, і запит виглядав моторошно:
А якщо потрібна підсумкова кількість? Наприклад, в адмінці сайту людина аналізує відвідуваність в певні періоди. Такий запит виконується повільно без індексу за датою:
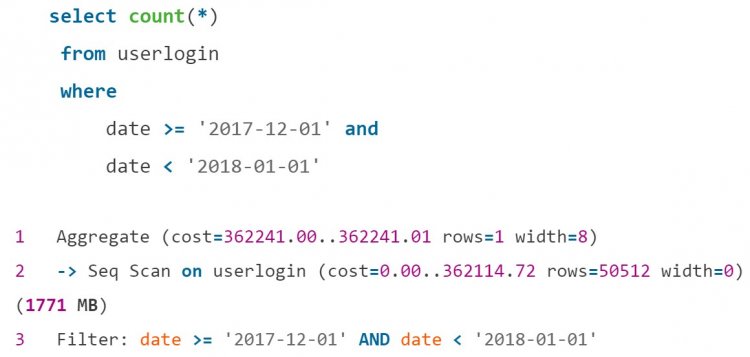
Але чи доцільно навішувати величезний індекс B-Tree на маленьку табличку? Послідовне сканування займало тут 5-6 хвилин. На допомогу прийшов Block Range Index (BRIN). BRIN-індекс повертає номери сторінок з відповідними даними і виконує перевірку всієї сторінки на відповідність умовам.
Оскільки він не зберігає ідентифікатори рядків і значення, його розмір значно менше: у BRIN-індексу - 72 KB, а для порівняння, у B-Tree - 216 Mb.
Ось результат оптимізації за допомогою BRIN-індексу:
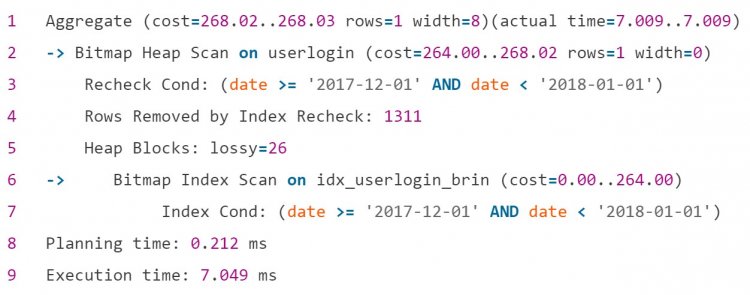
Такий маленький індекс легко підтримувати і зручно використовувати, коли значення колонок і фізичне розташування на диску корелюються, наприклад, для журналу. Документація рекомендує створювати цей індекс на багато колонок, якщо фільтруєте по ним. І тоді в зв'язці з операцією AND в умовах ви отримаєте чудову швидкість виконання.
Скорочуйте кількість інформації, що зберігається
Зменшуйте не тільки індекси, а й таблиці. Припустимо, в одній колонці у вас JSON зі старими даними, а в іншій - з новими.
Замість того, щоб зберігати кортеж повністю, позбудьтеся від дефолтних значень типу NULL і порожнього рядка. У другу колонку записуйте тільки змінені значення. Це заощадить не тільки місце на диску, але і час на резервне копіювання.

Як ще зменшити час на бекапи? Замініть тип timestamp на date, якщо час в таблиці нульовий. Так, розробники отримали економію 1,3 гігабайт на порожньому місці і скоротили час на щоденне резервне копіювання.

Оптимізуйте LIKE
Деякі вважають, що для запиту з LIKE не можна створити індекс. Думка помилкова, і тут вам стане в нагоді індекс SP-GIST, який розділить значення на окремі групи. Для рядків він створить окремі гілки на кожну букву:
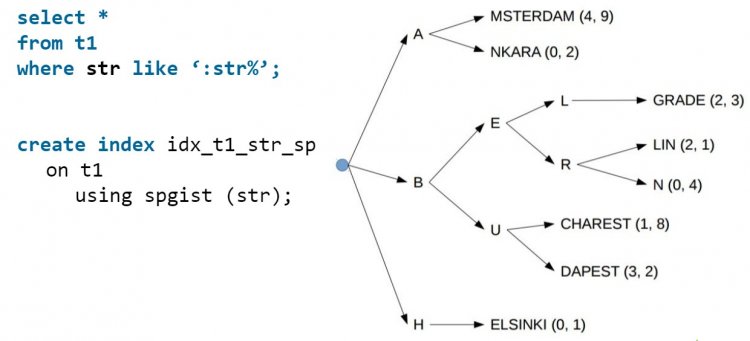
SP-GIST підійде для списків товарів, послуг, міст або інших рядків. При автодоповненні на сайті ви передаєте в запит перед знаком % те, що ввів користувач, а планувальнику навіть не доведеться лізти в купу, адже всі дані вже в індексі.
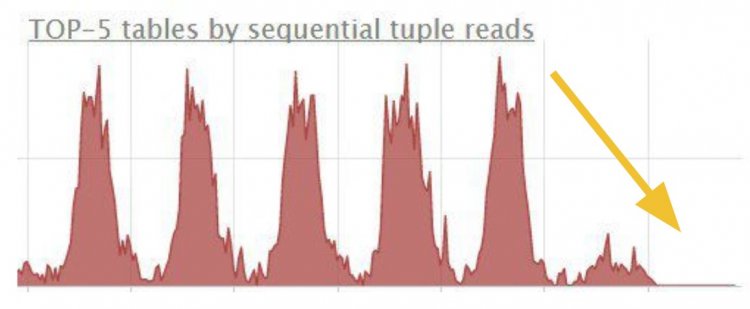
А що, якщо потрібне в довіднику слово йде не з початку рядка? Використовуйте GIN-індекс, схожий на алфавітний покажчик в книзі: він вказує номери сторінок, де ви вручну шукаєте потрібне слово.

В результаті підете від послідовних сканів і отримаєте прискорення запиту в кілька разів:
Застосовуйте Partial index
Partial index - індекси c обмеженням за умовою. Уявіть, що потрібна перевірка операцій компанії за останній рік за двома постійним умовам:
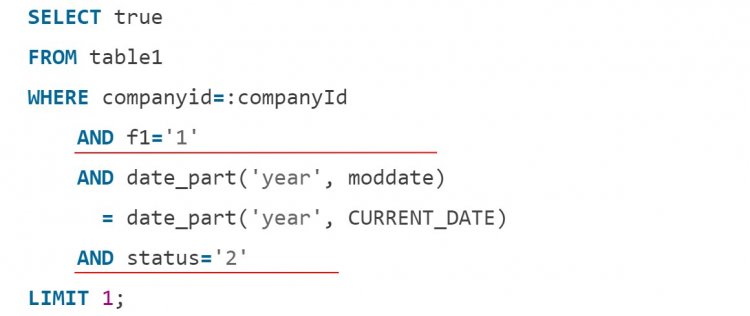
Замість написання попереднього обробника з чергою і перевірками, створіть маленький індекс з відібраними за умовою значеннями:

Тоді запит почне виконуватися тільки за індексом, а використання диска впаде до нуля:
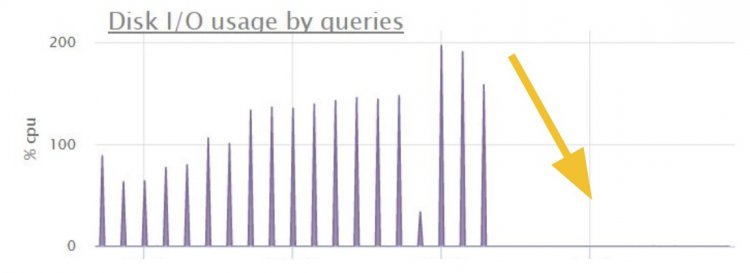
Розберіться зі складним сортуванням
У продуктів зустрічаються дуже складні правила сортування:
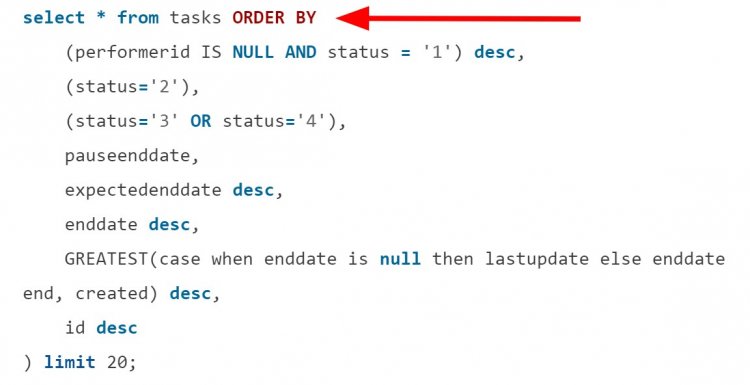
І в першу чергу розробники намагаються оптимізувати фільтрацію WHERE. У такій ситуації розгляньте створення індексу для складного сортування. Для прикладу вище така оптимізація скоротила час виконання і кількість сканів:
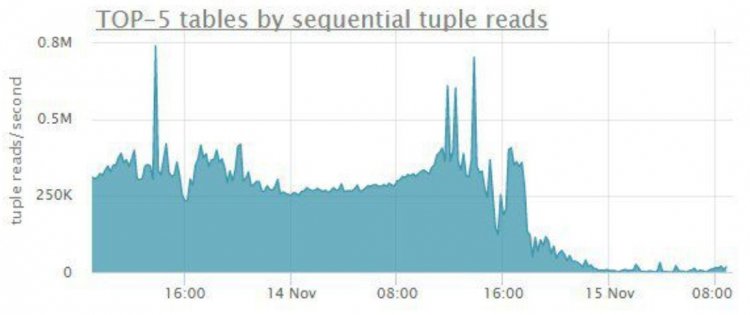
У прагненні написати все зараз не забувайте, що підзапити і UNION обходяться недешево. Подивіться на запит:

Коли в таблиці більше сотень тисяч відповідних записів, на етапі сортування диск впаде. А потрібно було 20 елементів.
Для вирішення питання створюють окрему таблицю або призначають єдину з необхідних майстер-таблицю. Переносите в неї дані з інших таблиць під іншими категоріями і отримуєте звичайний select * from mastertable замість об'єднань.
Аналізуйте код і плани запитів
Коли ви приходите до необхідності створення hints для планувальника запитів або костилів, щоб пояснити PostgreSQL, що робити, то перегляньте власну схему і код. Можливо, там доведеться все міняти.
Оскільки план запиту на локальній машині, в тестовому середовищі і в продакшені сильно відрізняється, то для аналізу планів в проді включають модуль auto_explain. Ви задаєте час виконання, перевищення якого буде сигналом для логування запиту.
Для отримання більш детальної інформації розробникам потрібні логи з продакшена. Щоб розібратися, згодуйте логи утиліті pgbadger і побачите звіт.
Висновок
Як бачите, навантажити базу даних на рівному місці простіше простого. Іноді розробники використовують важкі конструкції і приймають неправильні рішення через незнання. Не бійтеся зміни схеми бази даних, позбавляйтеся від зайвої інформації, перевіряйте код і структуру запитів, а також створюйте індекси.











0 комментариев
Добавить комментарий