Компания Google представила новый аудиокодек Lyra, оптимизированный для достижения максимального качества передачи речи даже при использовании очень медленных каналов связи. Код реализации Lyra написан на C++ и открыт под лицензией Apache 2.0, но в числе необходимых для работы зависимостей присутствует проприетарная библиотека libsparse_inference.so с реализацией ядра для математических вычислений. Отмечается, что проприетарная библиотека является временной - в дальнейшем Google обещает разработать открытую замену и обеспечить поддержку различных платформ.
По качеству передаваемых голосовых данных на низких скоростях Lyra существенно превосходит традиционные кодеки, в которых используются методы цифровой обработки сигналов. Для достижения высокого качества передачи голоса в условиях ограниченного объёма передаваемой информации, помимо обычных методов сжатия звука и преобразования сигналов, в Lyra применяется речевая модель на базе системы машинного обучения, позволяющая воссоздать недостающую информацию на основе типовых характеристик речи. Задействованная для генерации звука модель обучена с использованием нескольких тысячах часов с записями голосов на более чем 70 языках.

Кодек включает в себя кодировщик и декодировщик. Алгоритм работы кодировщика сводится к извлечению параметров голосовых данных каждые 40 миллисекунд, их сжатию и передаче получателю по сети. Для передачи данных достаточно канала связи со скоростью 3 килобита в секунду. Извлекаемые звуковые параметры включают в себя логарифмические мел-спектрограммы, учитывающие характеристики энергии речи в различных частотных диапазонах и подготовленные с учётом модели человеческого слухового восприятия.
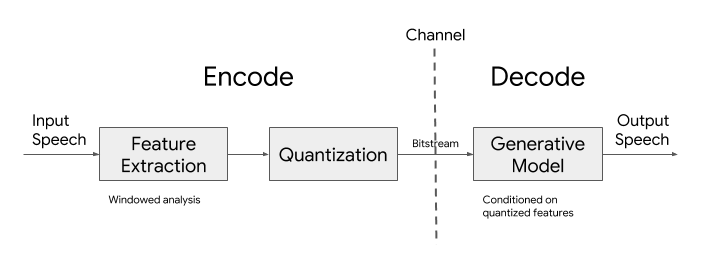
В декодировщике используется генеративная модель, которая на основе переданных звуковых параметров воссоздаёт сигнал с речью. Для снижения сложности вычислений применена лёгкая модель на основе рекурентной нейронной сети, представляющей собой вариант модели синтеза речи WaveRNN, в котором используется более низкая частота выборок, но генерируется параллельно сразу несколько сигналов в разном диапазоне частот. Полученные сигналы затем накладываются для получения единого выходного сигнала, соответствующего заданной частоте дискретизации.
Для ускорения также применены специализированные процессорные инструкции, доступные в 64-разрядных процессорах ARM. В итоге, несмотря на применение машинного обучения, кодек Lyra может применяться для кодирования и декодирования речи в реальном режиме времени на смартфонах среднего ценового диапазона, демонстрируя задержку передачи сигнала на уровне 90 миллисекунд.

0 комментариев
Добавить комментарий