Считается, что хорошая и дешевая инфраструктура — это миф и в реальной жизни так не бывает. Автоскейлинг, инфраструктура как код, Kubernetes, мониторинг и логирование — это звучит очень дорого. А что делать стартапу, у которого нет денег? DevOps-инженер и автор самого большого Telegram-канала о DevOps в Украине Олег Миколайченко рассмотрел два примера, как сделать осмысленную инфраструктуру за копейки и не ограничивать бизнес плохими решениями.

Когда строить инфраструктуру для стартапа
Часто случается так, что первая версия продукта готова, а запустить ее негде — просто нет инфраструктуры, или она в супер плачевном состоянии. Это очень печально — стартап теряет время, а конкуренты не спят.
Инфраструктура — это сервисы, процессы, площадки для запуска проекта. По сути, это вся обвязка продукта вместе с вычислительными мощностями. Это сервера, процессы разработки и выкатки, мониторинг, сервис для логов, и большое архитектурное видение: а что будет “если”.
Таких “если” может быть огромное количество (о которых нужно позаботиться еще до публичного релиза):
- если пойдет трафик,
- если появятся пользователи,
- если стартап купят,
- если пользователи не придут, и это будет мертвый продукт.
Я не раз был свидетелем, когда стартап продавали, а он настолько врос в своих основателей, что процесс смены всех доступов и учетных записей затягивался на месяцы.
Второй вариант, когда продукт слишком сильно врастает в существующий портфель продуктов компании, и вырезать его не получается даже за месяцы. В моем опыте было несколько поездок в офисы тех, кто покупал приложения, для передачи знаний и обучения нюансам работы системы.
В любом случае это дорого и долго, так что лучше закладывать оптимальный фундамент еще вначале.
В худшем случае вы запустите на этой же инфраструктуре другой стартап с другой идеей, в лучшем — получите масштабируемую управляемую платформу, которая будет легко поддерживаться, не ограничивать бизнес и не приносить проблем.
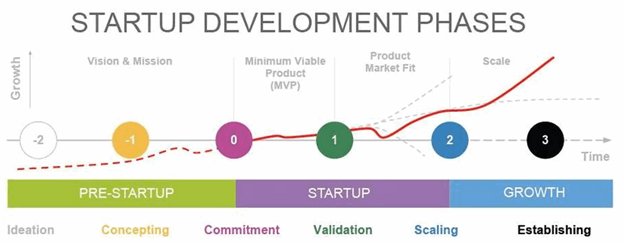
Допустим, гипотеза уже подтверждена и прошла этап валидации, вы решаете ее реализовывать, на выходе получаете продукт, несколько раз его меняете, попадаете в топ на Product Hunt и… занавес.
Единственный сервер, на котором работало приложение, упал от нагрузки. И дальше как в тумане: письмо провайдеру, время ожидания, перезагрузка, опять приходят пользователи, опять все очень плохо. Очень обидно.
Получается, что думать о масштабировании приложения нужно еще до публичного релиза. Второй вариант: провести нагрузочное тестирование, определить максимальную нагрузку и арендовать больше серверов, чем нужно. Такой вариант дороже — ведь мощности будут простаивать когда не используются, и за них в любом случае нужно платить.
Быстрый цикл обратной связи, быстрая разработка и частые релизы — это то, что нужно для стартапа.
В идеале, разработку продукта и инфраструктуры нужно запускать параллельно: процессы сборки и развертывания ускорят движение, в результате этап тестирования будет проходить намного быстрее — это даст возможность стартапу двигаться более реактивно.
Кто должен делать первую версию платформы
Я бы очень рекомендовал найти DevOps-инженера на part time — в результате он сможет за несколько дней реализовать нормальную начальную инфраструктуру по этой статье и лучшим практикам.
С другой стороны, если вы — разработчик, или у вас мало ресурсов — можно сделать и своими силами, следуя рекомендациям, просто это будет дольше.
Чего у вас больше — денег или времени — решать только вам.
Рассмотрим ситуацию: в кармане с названием “инфраструктура” есть $20. Что делать в таком случае?
Best practises дизайна инфраструктуры
В первой части статьи мы поговорили о самых распространенных набитых шишках, а теперь давайте их избегать. Требования собрать нужно до того, как планировать бюджет и распределять $20.
Разберем по очереди, что важно:
1. Масштабируемость
Какая разница, сколько времени потрачено на валидацию гипотезы и разработку, если на публичном релизе полная лажа. Инфраструктура должна быть спроектирована с учетом роста, ведь это самое важное для стартапа. Эту проблему решает Kubernetes + облачный провайдер.
Пришло 1000 пользователей — хорошо, увеличим количество виртуальных серверов в облаке. Пришло 10000 — ладно, еще увеличим. Начинает подтормаживать база данных (а мы это видим по графикам мониторинга) — окей, увеличиваем ее размер или тип.
Всегда нужно руководствоваться здравым смыслом: шардирование БД для стартапа — нет, увеличение размера виртуального сервера БД — да.
2. Инфраструктура как код
К счастью, в 2020 году никто инфраструктуру руками не поднимает. Если ваш инженер так делает — скорее всего у вас нет инженера. Изменения “руками” подразумевают огромное количество рутинных действий, приводят к ошибкам, никто никогда не знает, в каком состоянии инфраструктура. Никому не понятно, как оно вообще работает и может работать. Эти проблемы принято решать с помощью Terraform.
3. Цена
Круто, если мы можем запустить приложение и платить за инфраструктуру копейки. Если мы стартап на начальном этапе, то денег еще не зарабатываем — чем меньше стоит инфраструктура, тем больше времени можем пробовать “выстреливать”.
4. Фокус на пользе
Все что не касается приложения и базовой инфраструктуры нужно максимально выносить в SaaS. Нужен мониторинг? Datadog или Newrelic. Некуда складывать логи? Logentries или LogDNA. Нечем собирать приложение? TravisCI, CircleCI или Github Actions.
Если пытаться поднимать и сопровождать свой Jenkins, Prometheus, Elastic stack — будет и сложно, и неэффективно.
5. Отдельные аккаунты и кредитки
Заведите отдельный почтовый ящик для регистраций сервисов и отдельную банковскую карту для оплаты услуг. Это суперполезный совет с любой точки зрения.
Serverless в AWS: сначала копейки, потом камаз
Самое первое решение, которое прямо “выпрашивает” решить проблему дешевой инфраструктуры для стартапа — serverless архитектура. В двух словах, мы договариваемся: сервера не нужны, не хотим о них знать ничего вообще, и мыслим концепциями функций.
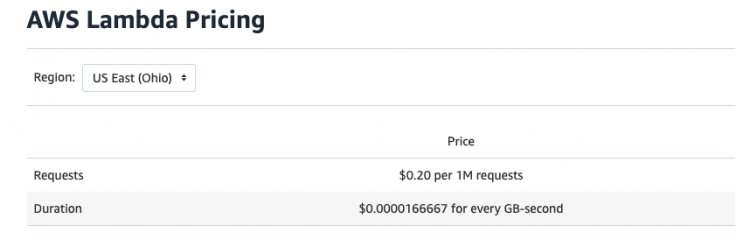
Возьмем самое логичное решение: Lambda + API Gateway. Это работает так: описываем бизнес логику в Lambda-функциях, и сверху накручиваем роутинг между несколькими функциями с помощью API Gateway.
Огромное преимущество такого подхода — копеечная стоимость, и только по факту использования ресурсов. Получается, что пока у нас нет трафика и пользователей — мы практически ничего не платим, когда идет первый трафик — начинаем платить за каждый запрос.
Второе преимущество — масштабирование из коробки. Внезапные A/B тесты, которые гонят трафик, никак не отразятся на стабильности: каждый пользователь будет обслужен.
Концепция инфраструктуры как код будет отлично работать и позволит описать все ресурсы в Terraform (и несколько окружений для разработки, быстрые релизы).
Дополнительно из коробки будет базовый мониторинг, базовое логирование — и это все стоит очень дешево, пока продукт никто не использует.
Самое сильное преимущество — фокус на пользе. По сути, все работает само по себе: остается только разрабатывать бизнес логику и ни о чем больше беспокоится не нужно.
Минусы тоже есть:
- vendor lock (если мы спроектируем serverless систему внутри AWS, мы будем ограничены только этим облаком);
- дополнительная оплата за каждое движение: трафик, логи, мониторинг, время, ресурсы;
- это будет стоить камаз денег, когда придет реально много пользователей;
- это будет стоить камаз денег, если систему мы спроектируем неправильно (занимать больше памяти, чем нужно, длительное время выполнения и т.д.).
Получается, что это идеальный вариант, если вы тестируете идею и не ждете огромного количества запросов и пользователей. Классный вариант, если вы получили финансирование от AWS или зарегистрировались на free tier. Если есть нагрузка — будет дорого и супер неудобно.
Kubernetes в DigitalOcean: $20 в месяц
Моя личная рекомендация — смотреть в сторону любых реализаций Kubernetes, для того чтобы не переделывать инфраструктуру каждые полгода-год. По состоянию на сейчас Kubernetes стал фактически стандартом рынка, это ведущая область которая развивается и поддерживается и сюда однозначно есть смысл вкладывать время и деньги.
Для бизнеса Kubernetes предоставляет платформу, в которой из коробки доступно масштабирование, высокая доступность, стратегии деплоймента и огромное количество интеграций.
Kubernetes поддерживают Google, CNCF и очень большое сообщество.
DigitalOcean — это один из самых дешевых облачных провайдеров. Пару месяцев назад они выпустили сервис DigitalOcean Kubernetes — как раз то, что нам нужно. Managed Kubernetes означает, что мы получим все преимущества платформы, но не будем заботиться о конфигурации, управлении и сопровождении самого Kubernetes.
Альтернативы для PaaS Kubernetes — AWS EKS ($120/месяц за пустой Kubernetes cluster), GKE (от $50 за 2 самые маленькие ноды) — намного дороже, но в то же время более production-ready. Можно рассмотреть как вариант миграции, когда у стартапа появятся деньги.
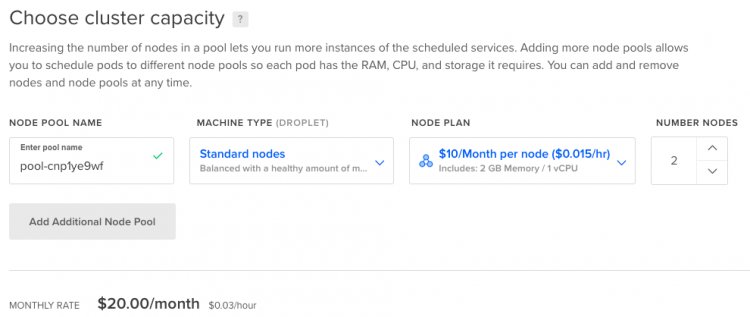
Самая дешевая конфигурация — это два виртуальных сервера (можно и один, но тогда будет не отказоустойчиво, так что нельзя один).
DigitalOcean Kubernetes (DOKS) поддерживает концепцию инфраструктуры как код. Ресурсы и провайдер доступны в Terraform и конфигурируются супер просто. Готовый Kubernetes кластер создается буквально одним ресурсом и несколькими строчками кода.
Если в AWS Lambda за дополнительные деньги были сразу доступны Cloudwatch для логирования, Cloudmetrics для мониторинга и X-Ray для более детального понимания, что происходит с приложением, то в DOKS такого нет. Есть совсем базовые бесплатные графики по потребляемой памяти, нагрузке процессора и сети, но этого, очевидно, мало.
С точки зрения масштабируемости у нас есть возможность скейлится как вертикально (увеличивая размер и тип виртуального сервера), так и горизонтально (автоматически увеличивая количество серверов в кластере). Горизонтальная масштабируемость доступна по умолчанию, и работает примерно так:
- В зависимости от метрики (загрузка процессора, память, сеть) DOKS определяет, что нужно добавить виртуальный сервер в кластер;
- Kubernetes понимает, что появился новый сервер, и перемещает туда часть приложений;
- Когда нагрузка ушла, DOKS постепенно убирает сервера из кластера;
- Победа: мы заплатили только за пару часов, пока была нагрузка.
Для того, чтобы реализовать детальный мониторинг и логирование в мире Kubernetes, принято использовать prometheus-operator и Elastic stack. Эти сервисы устанавливаются внутрь кластера и занимают ресурсы. Мы строим инфраструктуру за $20, так что лишних ресурсов у нас нет. Давайте смотреть, как мы можем выйти из этой ситуации.
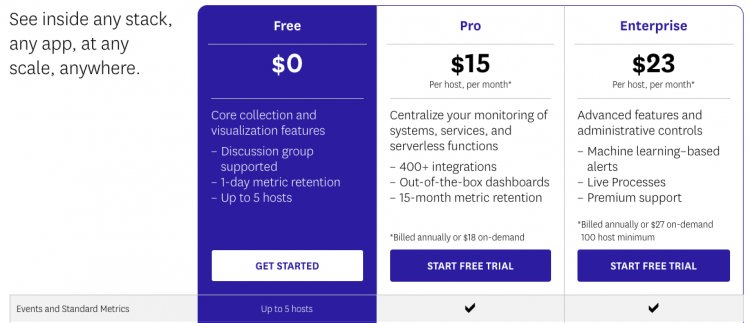
Из всех SaaS систем мониторинга бесплатный план я нашел только у Datadog. С помощью Datadog мы сможем собирать метрики с нашего кластера, смотреть графики в браузере и анализировать, почему наше приложение работает плохо.
Дополнительно могу рекомендовать использовать Sentry для начального анализа ошибок приложения. У них также есть бесплатный план.
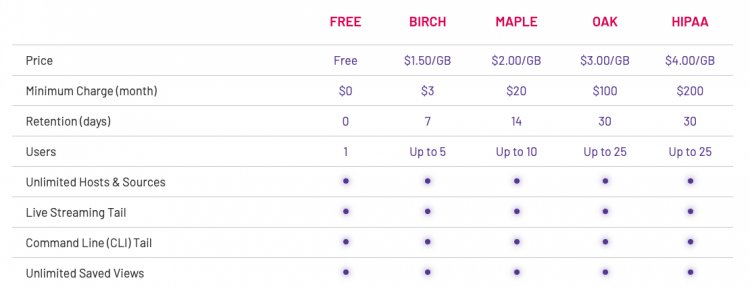
Из решений для логирования бесплатный план есть у LogDNA: нюанс в том, что логи будут удаляться через 24 часа. Это немного неудобно, потому что всегда хочется понимать, когда ошибка появилась впервые. Но для наших требований — более чем достаточно.
Стоит сказать, что все три этих продукта достаточно дороги даже на старте, если превысить лимиты бесплатного плана. Давайте будем реалистами: ресурсов маленького Kubernetes кластера и времени разработчиков не хватит, чтобы поддерживать свой мониторинг, сервис сбора логов и анализа ошибок. Скорее всего с ростом инфраструктуры вы решите поддерживать свои решения, а пока нужно двигаться быстро — SaaS-решения будут отличным вариантом.
Для старта этого будет более чем достаточно.
А как же дешевые spot instances?
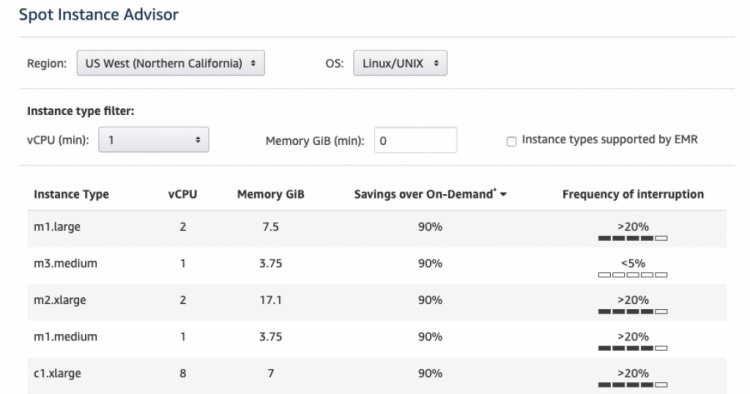
Да, отличная идея. Но не для первого релиза.
Spot instances — это виртуальные сервера, которые могут стоить дешевле до 90% в самых популярных облачных провайдерах. Их хитрость в том, что эти сервера могут у вас забрать в любой момент, или их может не быть вовсе.
Получается, что приложение должно быть спроектировано специальным образом: дополнительно нужно реализовать graceful shutdown (правильное завершение работы, оно нужно при масштабировании в том числе), добавить очереди сообщений в архитектуру и еще много нюансов. Такой подход — это усложнение продукта, и дополнительный лишний акцент не на основном бизнесе.
Если приложение уже в Kubernetes и туда можно легко добавить дополнительный кластер из spot серверов — супер, нужно добавлять.
Существенную экономию это принесет тогда, когда инфраструктура достаточно большая: а на начальных стадиях это принесет только лишнюю головную боль.
GCP Free Tier & AWS Free Tier
Практически у всех облачных провайдеров есть бесплатный тестовый период, который может быть очень полезен для экономии денег. В большинстве случаев это какая-то определенная сумма денег сроком на 1 год, которую можно потратить используя полезные сервисы облачного провайдера.
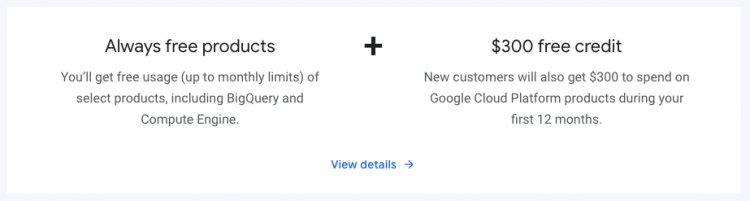
Google Cloud Platform дает $300 на 12 месяцев. Если попытаться построить Kubernetes cluster — это будет стоить около ~$50 в месяц. Получается, что этих денег хватит на 6 месяцев.
AWS Free Tier подразумевает использование определенных сервисов в пределах квот, тоже на 12 месяцев. К сожалению Kubernetes Engine не доступен в бесплатном периоде, но вполне можно построить serverless архитектуру, которую мы рассматривали разделом ранее.
Считается, что за этот тестовый период вам настолько понравится использовать облако, что вы начнете добавлять дополнительные сервисы: кеш, CDN, базы данных и прочее. В случае агрессивного использования можно очень легко подсесть на иглу: когда биллинг уже очень дорогой, а быстро переехать на более дешевое решение не получается. С этим нужно быть очень осторожными.
Также упомяну о Google Cloud for Startups и AWS for Startups. Если ваш стартап уже работает, есть пользователи, юридическое лицо, и вы можете показать рост на графиках — скорее всего у вас получится получить финансирование от облачных провайдеров.
Условия и возможности гибкие, в целом их можно характеризовать так: провайдеры ежемесячно будут выделять вам сумму, необходимую на развитие инфраструктуры, сроком до трех лет. За это время вы 100% научитесь пользоваться внутренними сервисами (агрессивный маркетинг и личный менеджер будет этому способствовать), а через какое-то время даже съезжать никуда не захотите.
Послесловие
Получается, что в реальной жизни можно запустить начальную масштабируемую инфраструктуру с высокой доступностью даже когда совсем нет денег. Конечно, $20/месяц — это минимальная сумма, с которой начинается самая первая версия самой маленькой инфраструктуры. С ростом стартапа будет расти количество серверов, их стоимость и цена дополнительных сервисов для логирования и мониторинга.
У нас получилась по-умолчанию масштабируемая инфраструктура (и для этого ничего не нужно делать дополнительно), мы использовали актуальный стек на рынке, и такое решение не нужно будет переделывать в ближайшее время.
В крайнем случае, Kubernetes дает вам возможность легко мигрировать с дешевого DigitalOcean Kubernetes на более дорогой Google Kubernetes Engine, или самый дорогой Amazon Kubernetes Engine после того, как придут инвестиции. В будущем будет возможность переехать и на свои сервера. В конце концов можно будет двигаться даже в сторону cloud agnostic: это когда платформа работает в нескольких облачных провайдерах одновременно.
Инфраструктура готова для развития, не ограничивает бизнес и стоит копейки. В крайнем случае, если текущая идея стартапа не взлетит — вы с легкостью запустите новую идею на существующей инфраструктуре.
Я буду супер рад и счастлив, если ваш стартап или продукт сможет пережить тяжелые времена или не ляжет под нагрузкой неожиданных пользователей благодаря этой методике. Если так случится, переведите мне пожалуйста 1% акций компании.











0 комментариев
Добавить комментарий