У 2010 році Деміс Хассабіс заснував стартап DeepMind Technologies з другом дитинства Мустафою Сулейманом та Шейном Легг, з яким познайомився в Університетському коледжі Лондона.
Засновники, щоб розвинути технологію AI, хотіли спробувати міждисциплінарний підхід - об'єднання ідей і досягнень в області машинного навчання, нейробіології, інженерії, математики, моделювання та обчислювальної інфраструктури.
У компанію інвестували венчурні фонди Horizons Ventures, Founders Fund, а також Ілон Маск і Скотт Баністер, співзасновник IronPort.
Команда DeepMind побачила потенціал в комп'ютерних іграх, які дослідники використовували для тестування AI. Одна з їхніх програм навчилася грати в 50 різних ігор Atari, а AlphaGo стала першою системою, яка перемогла професійного гравця в грі гo.

Злиття з Google
26 січня 2014 року Google оголосила про придбання DeepMind Technologies. Сума угоди склала від $400 до $650 млн. Купівля відбулася після того, як Facebook припинила переговори про придбання компанії в 2013 році. Після покупки стартап став називатися Google DeepMind.
На початку вересня 2016 року DeepMind перейшла в Alphabet, а з її назви зникла згадка Google.
Наукові прориви
AlphaZero і гра в шахи, сьогі і го
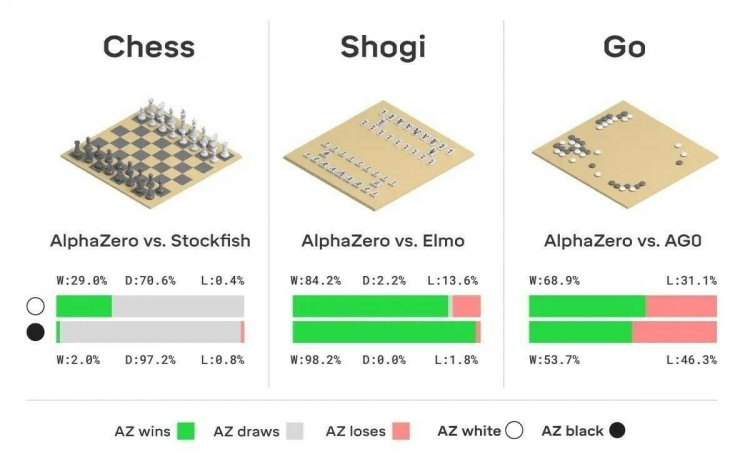
В кінці 2017 року DeepMind представила AlphaZero, систему, яка самостійно опановує гру в шахи, сьогі і го. Шахове співтовариство відзначило в іграх AlphaZero новаторський, високодинамічний і «нетрадиційний» стиль.
Непідготовлена нейронна мережа, навчаючись, грає сама з собою мільйони партій. Такий метод відомий як навчання з підкріпленням. Згодом AlphaZero вчиться на виграші, програші і нічиїх, коригуючи параметри нейронної мережі, що дозволяє приймати правильні рішення в наступних іграх.
Кількість тренувань, яких потребує мережу, залежить від стилю і складності гри: близько 9 години для шахів, 12 годин для сьогі і 13 днів для го.
Навчену систему протестували на найсильніших платформах для шахів (Stockfish) і сьогі (Elmo), а також на попередній версії системи AlphaGo Zero, найсильнішому з відомих гравців в го.
Stockfish і Elmo використовували 44 ядра процесора (як на чемпіонаті світу TCEC ), тоді як AlphaZero і AlphaGo Zero використовували одну машину з чотирма TPU першого покоління і 44 ядрами. Всі матчі проводилися з контролем часу: три години на гру, додаткові 15 секунд на кожен хід.
У кожній грі AlphaZero перемагала свого супротивника:
- У шахах AlphaZero перемогла Stockfish, чемпіона світу TCEC (дев'ятий сезон) 2016 року, вигравши 155 і програвши 6 ігор з 1000.
- У сьогі AlphaZero перемогла версію Elmo, чемпіона світу CSA 2017 року, вигравши 91,2% ігор.
- У го AlphaZero перемогла AlphaGo Zero, вигравши 61% ігор.
За думку DeepMind, для створення інтелектуальних систем, здатних вирішувати реальні проблеми, необхідно, щоб вони були гнучкими і адаптувались до нових ситуацій.
Системи, котрі опановують конкретні навички, часто не справляються навіть із злегка зміненими завдання. Уміння AlphaZero вчитися грати в шахи, сьогі і го демонструє, що алгоритм може отримувати нові знання в різних ситуаціях.
В майбутньому, відзначають в DeepMind, це може допомогти в створенні системи AI для вирішення наукових проблем.
Генеративна мережа запитів (DQN): ігри Atari
Мета DeepMind - створити штучних агентів, які зможуть досягти такого самого рівня продуктивності і універсальності, як у людини
Агенти структурують і вивчають дані, одержувані, наприклад, за допомогою глибокого навчання нейронних мереж. Для створення перших штучних агентів в DeepMind вперше застосували глибоке навчання з підкріпленням (RL).
Агенти DeepMind постійно виносять оціночні судження, вибираючи хороші дії замість поганих. Ці знання представлені Q-мережею, вона оцінює загальну винагороду, яку агент може отримати після виконання певної дії.
У 2017 році DeepMind представила перший успішний алгоритм глибокого навчання з підкріпленням. Ключова ідея - використання глибоких нейронних мереж для подання Q-мережі і її навчання для прогнозування загальної винагороди.
Попередні спроби об'єднати навчання з підкріпленням і нейронні мережі були невдалими через нестабільне навчання. Щоб усунути проблеми, алгоритм Deep Q-Network (DQN) зберігає весь досвід агента, а потім випадково відбирає і відтворює цей досвід для надання різноманітних навчальних даних.
DeepMind застосувала DQN для навчання алгоритму ігор для консолі Atari 2600. На кожному часовому кроці агент спостерігає необроблені пікселі на екрані, сигнал винагороди, відповідний рахунок в грі, і вибирає напрямок джойстика. DeepMind навчила окремих агентів DQN для 50 різних ігор Atari без будь-якого попереднього знання правил.
DQN досягла людського рівня майже в половині з 50 ігор. Вихідний код DQN і емулятор Atari 2600 знаходяться у вільному доступі.
Удосконалення привели до 300-процентного поліпшення середнього показника в іграх Atar; продуктивність на людському рівні досягнута майже у всіх іграх на цій приставці.
Компанія також створила систему RL, відому як Goril, яка використовує платформу Google Cloud для прискорення навчання.
Пізніше DeepMind представила ще більш ефективний метод, заснований на асинхронному RL. Цей підхід використовує багатопоточність стандартних процесорів.
Ідея в тому, щоб одночасно створити безліч агентів, але з використанням загальної моделі. Це забезпечує життєздатну альтернативу досвіду відтворення, оскільки розпаралелювання також диверсифікує і декорелює дані.
Крім того, DeepMind розробила ряд методів глибокого RL для задач безперервного контролю на кшталт маніпуляцій з роботами і локомоції.
DeepMind розробила алгоритм RL, який вивчає як мережу цінностей (яка передбачає переможця), так і мережу політик (яка вибирає дії) за допомогою ігор AlphaGo об'єднала ці глибокі нейронні мережі.
У березні 2016 року AlphaGo перемогла в го Лі Седола - найсильнішого гравця останнього десятиліття з 18 світовими титулами.

Нейронна мережа з динамічною пам'яттю
В недавній статті DeepMind показала, як об'єднати нейронні мережі та системи пам'яті для створення машин, які зберігають знання і алалізують їх.
Вони задіюють пам'ять для відповіді на питання про складні структуровані дані, включаючи штучно створені історії, родоводи і карти метро.
Також DeepMind показала, що алгоритм може вирішити головоломку з використанням навчання з підкріпленням. Зараз розробники тільки починають створювати нейронні мережі, які можуть обмірковувати відповідь таміркувати, використовуючи знання.
У комп'ютері процесор зчитує інформацію з оперативної пам'яті (ОЗУ) і записує в неї нову. ОЗУ дає процесору набагато більше місця для організації проміжних результатів обчислень. Тимчасові наповнювачі називаються змінними і зберігаються в пам'яті.
Змінні містять числове значення. Структури даних - змінні в пам'яті, які містять посилання, за якими можна переходити до інших змінним.
Одна з найпростіших структур даних - список: послідовність змінних, які можна читати за елементами. Наприклад, можна зберегти список імен гравців в спортивній команді, а потім прочитати кожне ім'я по одному.
Більш складна структура даних - дерево. Наприклад, в сімейному дереві можна переходити за посиланнями від дітей до батьків, щоб прочитати родовід.
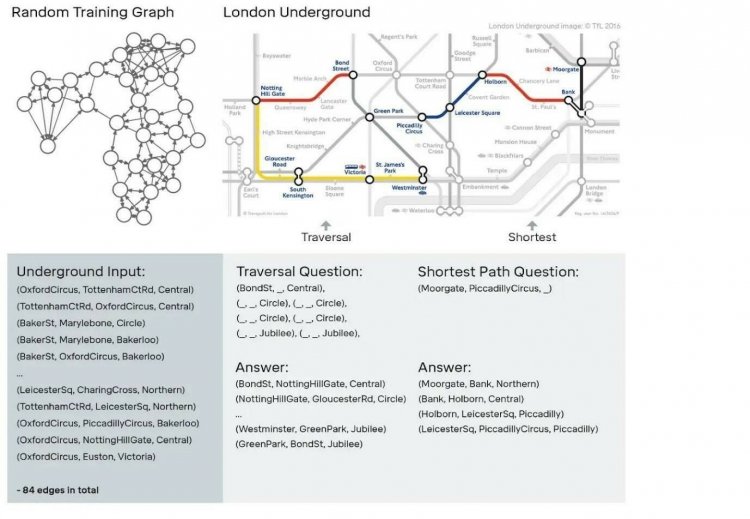
Одна з найскладніших і загальних структур даних - граф, подібний мережі лондонського метро.
Проектуючи DNC, розробники хотіли створити машини, які могли б навчитися самостійно формувати складні структури даних і орієнтуватися в них. В основі DNC лежить нейронна мережа, контроллер, аналогічний процесору в комп'ютері.
Контролер відповідає за введення даних, читання, запис в пам'ять і за виведення-відповідь. Пам'ять являє собою набір місць розташування, кожне з яких може зберігати вектор інформації.
Контролер виконує кілька операцій з пам'яттю: він вибирає, записувати дані в пам'ять чи ні.
Якщо всі місця в пам'яті витрачені, контролер звільняє деякі, як комп'ютер перерозподіляє пам'ять, яка більше не потрібна. Записуючи щось, комп'ютер відправляє вектор інформації в вибране місце в пам'яті.
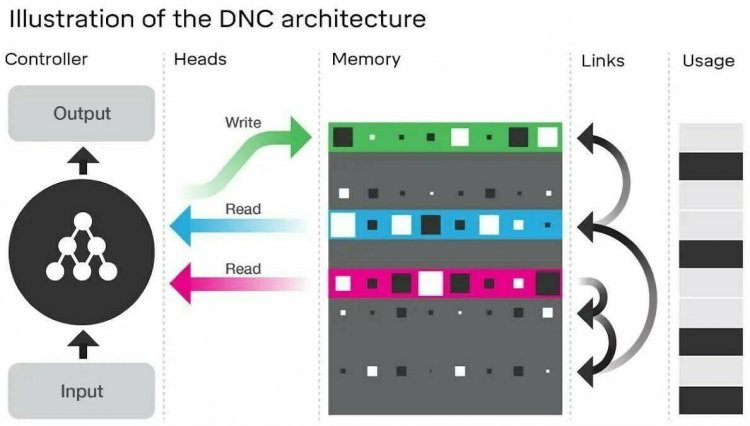
На зображенні нейронний мережевий контролер (ліворуч) отримує зовнішні сигнали і на їх основі взаємодіє з пам'яттю, використовуючи операції read або write. Щоб контролеру було простіше переміщатися по пам'яті, DNC зберігає «тимчасові посилання», стежачи за тим, що було написано, і записує поточний рівень «використання» кожного місця розташування пам'яті.
DNC самостійно вчиться записувати описи і відповідати на питання про них. Коли DeepMind описувала станції і лінії лондонського метро, розробники могли попросити DNC відповісти питання, як дістатися з Моргате до Пікаділлі.
DNC навчався на випадково згенеруванних графах (на зображенні зліва). Після дослідники перевірили, чи зможе DNC правильно переміщатися в лондонському метро.
На прикладі сімейного древа DeepMind показала, що DNC може відповідати на питання, що вимагають складних висновків. Описуючи тільки відносини батьків, дітей, братів і сестер, розробники запитували, наприклад, хто такий предок Фрей по материнській лінії.
Звичайні нейронні мережі в таких порівняннях не могли зберігати інформацію або навчитися міркувати, узагальнюючи нові приклади.
WaveNet - генеративная модель для необробленого аудіо
WaveNet - мова, що імітує будь-який людський голос. Цю ж мережу, як показала DeepMind, можна використовувати для синтезу музики.
Однак синтез мови, або перетворення тексту в мову (TTS), - все ще сильно покладається на так звану конкатенацію TTS , де велика база даних коротких фрагментів мови записується одним диктором, а потім рекомбінують для формування повних висловлювань.
Це ускладнює зміна голосу (наприклад, перемикання на іншого або зміна акценту, емоцій) без запису нової бази даних. З'явилася потреба і в параметричному TTS , де вся інформація, необхідна для генерації даних, зберігається в параметрах моделі, а вміст і характеристики мови можна контролювати.
Поки параметричний TTS звучить менш природно, ніж конкатенаціонний. Існуючі параметричні моделі зазвичай генерують аудіосигнали, пропускаючи виходи через алгоритми обробки сигналів - вокодер.
WaveNet же моделює необроблену форму звукового сигналу безпосередньо, по одній вибірці за раз.
Дослідники, як правило, уникають моделювання необробленого звуку, тому що він відтворюється швидко: 16 тисяч семплів в секунду або більше.
Побудова повністю авторегресійної моделі, в якій на прогноз для кожної з цих вибірок впливають всі попередні (в статистиці кожен прогнозний розподіл обумовлено всіма попередніми спостереженнями), - складне завдання.
Однак моделі PixelRNN і PixelCNN, опубліковані в 2019 році, показали, що можна створювати складні природні зображення не тільки по одному пікселю за раз, але і по одному кольоровому каналу за раз. Це надихнуло DeepMind на адаптацію двовимірних PixelNets до одновимірної мережі WaveNet.
Компанія навчила WaveNet, використовуючи набори даних TTS від Google в оцінці продуктивності алгоритму.
На малюнку нижче - якість WaveNet для різних мов за шкалою від одного до п'яти в порівнянні з кращими сучасними системами TTS Google, а також з людською мовою, що використовує середні оцінки думок (MOS) .
MOS - стандартна міра для суб'єктивних тестів якості звуку. Мережі WaveNet скорочують розрив більш ніж на 50% як для англійської, так і для китайської мов.
Щоб використовувати WaveNet для перетворення тексту в мову, потрібно повідомити алгоритму, який перед ним текст. Для цього DeepMind перетворює текст в послідовність лінгвістичних і фонетичних функцій (які містять інформацію про поточну фонему, склад, слово і так далі) і подає її в WaveNet.
Таким чином, передбачення мережі обумовлені не тільки попередніми аудіосемплами, але і текстом, який потрібно вимовити.
Оскільки WaveNet можна використовувати для моделювання будь-якого аудіосигналу, в DeepMind спробували згенерувати музику. На відміну від експериментів TTS, розробники не визначали для мереж вхідну послідовність, яка вказує, що грати (наприклад, музичний супровід); замість цього алгоритму просто дозволили генерувати все, що він хоче.
Продовження в 2 частині.











0 комментариев
Добавить комментарий